Datasets
Open Access
Brazilian Coin Detection Dataset
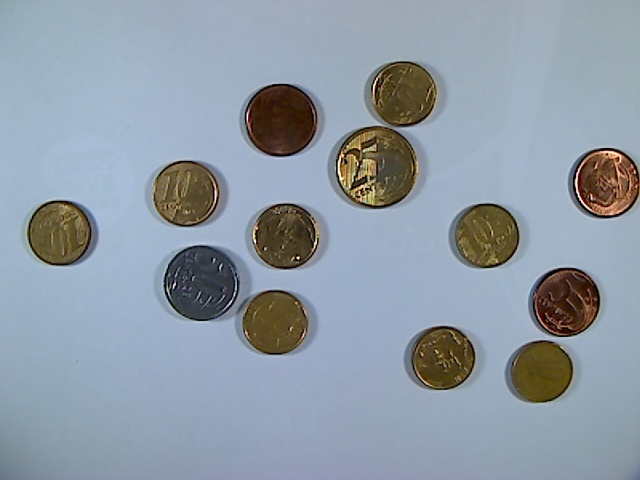
- Citation Author(s):
-
DavidYonekura
 Amazonas State UniversityElloáGuedesAmazonas State University
Amazonas State UniversityElloáGuedesAmazonas State University - Submitted by:
- David Yonekura
- Last updated:
- Wed, 05/06/2020 - 11:13
- DOI:
- 10.21227/kj4c-y809
- Data Format:
- License:
 1458 Views
1458 ViewsAbstract
This dataset is a collection of images and their respective labels containing examples of multiple Brazilian coins, the primary purpose is to support the development of Computer Vision techniques for automatic detection of such objects, i.e., localization and classification tasks.
It contains coins of R$ 0.05, 0.10, 0.25, 0.50 and 1.00 in Brazilian currency from the 2nd family, as manufactured by Casa da Moeda (http://www.casadamoeda.gov.br) since 2010. The samples were collected with a mobile phone and contain multiple coins placed upon a flat white A4 sheet of paper.
Labels were obtained from a group with several individuals from both sexes and detailed reviewed. Each label has a circular or polygon shape and denotes the corresponding value in cents of the coin it is related to. This dataset is an improvement from Brazilian Coins (available at https://www.kaggle.com/lgmoneda/br-coins) where location labels were created.
The dataset is divided in classification and regression, where the classification set contains 3056 images with a single coin and its respective annotation file, the regression set contains all the images from the classification set and other images with several coins and labels, amounting to 6021 images.
This dataset provides two annotations formats, the labelme and COCO format;
The labelme format consists of one json per image, where the labels can assume one of two types: circle or polygon; A circle label has a center and edge point, and a polygon is a set of points (Polygons where used for partial coins).
The COCO format, consists of a single json for the dataset.
Scripts for visualization are provided for both formats.
Further information about the formats can be found on the following links:
https://github.com/wkentaro/labelme
Acknowledgments:
Moneda thanks Luciana Harada and Rafael de Souza, his group in the college course that generated these datasets. Yonekura and Guedes acknowledge the grant PPP 04/2017 provided by FAPEAM/CNPq and the label review carried out by Natan Siqueira.
Dataset Files
 classification dataset classification.zip (155.94 MB)
classification dataset classification.zip (155.94 MB)- regression dataset regression.zip (395.80 MB)
 coco visualization script coco_view.py (2.50 kB)
coco visualization script coco_view.py (2.50 kB)- labelme visualization script labelme_view.py (1.81 kB)
Open Access dataset files are accessible to all logged in users. Don't have a login? Create a free IEEE account. IEEE Membership is not required.





