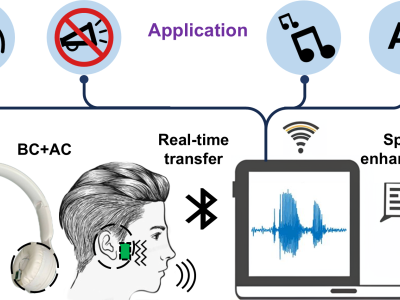
Speech recognition in noisy environments has long posed a challenge. Typically used air conduction microphone (ACM) is susceptible to environmental noise.
- Categories:
Speech recognition in noisy environments has long posed a challenge. Typically used air conduction microphone (ACM) is susceptible to environmental noise.

Due to the need for a flexible vocabulary and the high cost of collecting speech corpora, vocabulary independence of speech recognition systems has grown to be a significant issue. We describe the steps required to reach the objective of vocabulary-independent speech recognition and discuss our experimental experience with telephone speech recognition.

This paper is a novel digital signal processing software of the advanced conversion of text-to-speech synthesis technology, which has been available as a range of hardware products for more than ten years, to software. It was initially created as a replacement for character cell terminals and telephony applications, but it is now also used to give people who are visually impaired access to information. With a digital formant synthesizer used to mimic the human vocal tract, text-to-speech quality is very high in both understandability and naturalness.

100 Speakers each consisting of 5 voice samples for training data and 1 voice sample for testing data. Total of 600 voice samples collected in different audio formats like mpeg, mp4, mp3, ogg etc. These samples were than preprocessed and converted into .wav format. Each voice sample has a time duration of 5-10 seconds due to different lengths tuning of parameters should be done before usage. Whole Dataset size is 600mb and duration is 1 hour 40 minutes. This dataset can be used for speech synthesis, speaker identification.
100 Speakers each consisting of 5 voice samples for training data and 1 voice sample for testing data. Total of 600 voice samples collected in different audio formats like mpeg, mp4, mp3, ogg etc. These samples were than preprocessed and converted into .wav format. Each voice sample has a time duration of 5-10 seconds due to different lengths tuning of parameters should be done before usage. Whole Dataset size is 600mb and duration is 1 hour 40 minutes. This dataset can be used for speech synthesis, speaker identification.
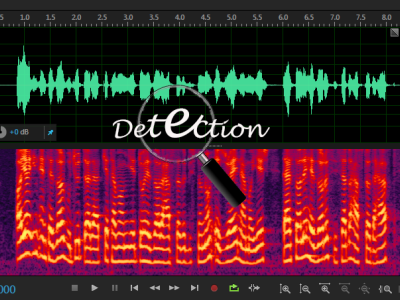
Speech detection systems are known as a type of audio classifier systems which are used to recognize, detect or mark parts of audio signal including human speech. Here, a novel robust feature named Long-Term Spectral Pseudo-Entropy (LTSPE) is proposed to detect speech and its purpose is to improve performance in combination with other features, increase accuracy and to have acceptable performance. Experimental results show that if LTSPE is combined with other features, performance of the detector is improved.