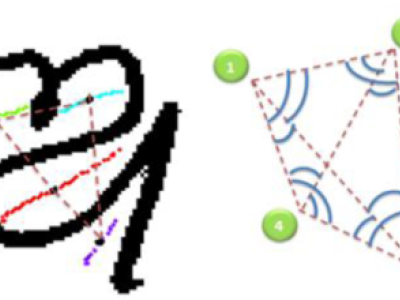
The "Sanskrit Character Dataset" includes 44 classes of handwritten Sanskrit characters, designed to support research in optical character recognition (OCR) and machine learning for ancient languages. Each class represents a unique Sanskrit letter, collected in various handwriting styles to ensure diversity and robustness. For each class, 50 to 80 images are included. To ensure diversity and real-world applicability, the letters were written in various handwriting styles.
- Categories: