Automated Software Engineering

Large Language Models (LLMs) have been widely used to automate programming tasks. Their capabilities have been evaluated by assessing the quality of generated code through tests or proofs. The extent to which they can reason about code is a critical question revealing important insights about their true capabilities. This paper introduces CodeMind, a framework designed to gauge the code reasoning abilities of LLMs through the following explicit and implicit code reasoning tasks: Independent Execution Reasoning (IER), Specification Reasoning (SR) and Dynamic Semantics Reasoning (DSR).
- Categories:
 21 Views
21 Views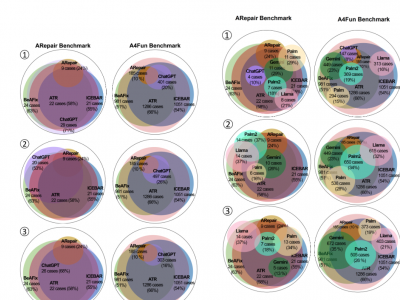
The growing adoption of declarative software specification languages, coupled with their inherent difficulty in debugging, has underscored the need for effective and automated repair techniques applicable to such languages. Researchers have recently explored various methods to automatically repair declarative software specifications, such as template-based repair, feedback-driven iterative repair, and bounded exhaustive approaches. The latest developments in Large Language Models (LLMs) provide new opportunities for the automatic repair of declarative specifications.
- Categories:
233 Views
The dataset is based on the latent faults detected by the popular OSS static code analysis tool, sonarQube Community Edition. The dataset is populated using the latent faults found in popular Java software from the open source repository GitHub . This dataset was specifically developed to identify the significant latent faults that affect the reliability of Java programs. This dataset can be used in its current form to conduct experiments with machine learning algorithms and to infer new reliability characteristics of Java programs. Please refer to the documents associated with sona
- Categories:
21 Views
This data set contains 120 text files describing the functional requirements written in natural language (English) for various software systems, such as educational, business, and hospitality settings. The dataset is ready for all text processing such as learning and extracting conceptual models.
- Categories:
2963 Views
FARLEAD2 receives a test scenario from the developer, and verifies a related functional behavior by witnessing the test scenario in the Application Under Test, on a real mobile device. The 'results.zip' file contains 204 Comma-Separated Values (CSV) files and a Perl script 'createtable.pl' that generates Table 2 in the manuscript. Each CSV file contains the results of ten runs of a witness generator for a test scenario under a given level of information. The experimental test scenarios are located in the 'scenarios.zip' file.
- Categories:
11 Views
The dataset contains Software Development Effort Estimation (SDEE) metrics values extracted from around 1800 Open Source Software (OSS) repositories of GitHub.
- Categories:
4255 Views