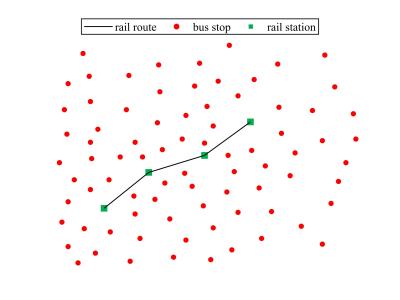
The dataset can be used to deal with the optimization design of feeder-bus network related to urban rail transit. The research on the optimization design of feeder-bus network related to urban rail transit is helpful to improve passengers' travel satisfaction and convenience, and solve the connection problem between rail transit station and bus stop. The dataset contains a 4 km by 5 km area, providing the coordinates of 80 bus stops and 4 rail transit stations.
- Categories:


