First Name
Shubham
Last Name
Tayade
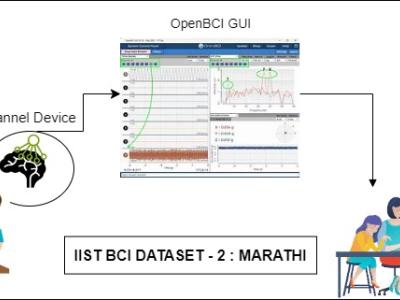
Problems of neurodegenerative disorder patients can be solved by developing Brain-Computer Interface (BCI) based solutions. This requires datasets relevant to the languages spoken by patients. For example, Marathi, a prominent language spoken by over 83 million people in India, lacks BCI datasets based on the language for research purposes. To tackle this gap, we have created a dataset comprising Electroencephalograph (EEG) signal samples of selected common Marathi words.