Datasets
Standard Dataset
Simulation results for "smooth water surface - cloudy atmosphere" system
- Citation Author(s):
-
DobroslavEgorov
 Kotel'nikov Institute of Radio Engineering and Electronics of RAS
Kotel'nikov Institute of Radio Engineering and Electronics of RAS - Submitted by:
- Dobroslav Egorov
- Last updated:
- Fri, 07/14/2023 - 06:29
- DOI:
- 10.21227/r5zc-7y90
- Data Format:
- Links:
- License:
 199 Views
199 Views- Categories:
- Keywords:
Abstract
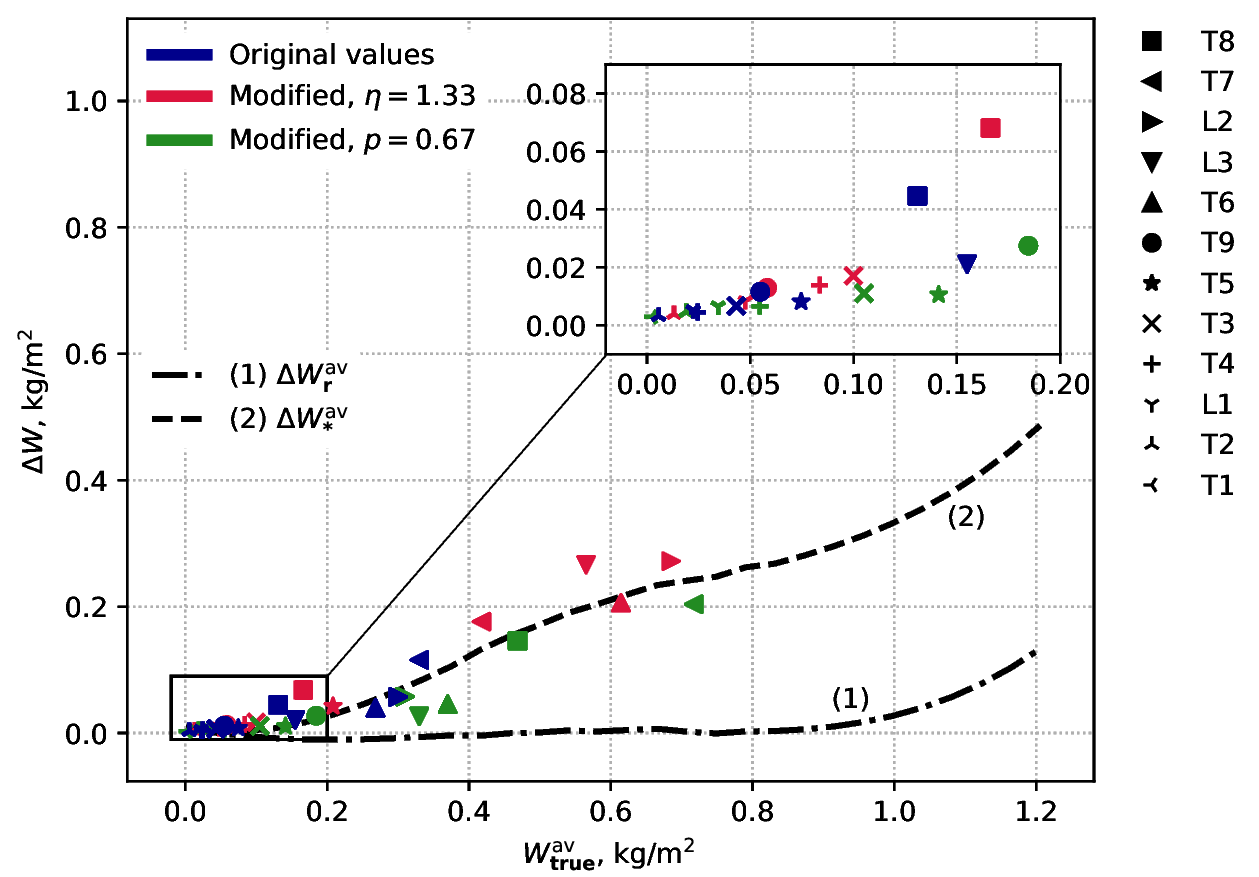
A computational experiment has been performed in order to evaluate systematic errors of atmospheric Total Water Vapor (TWV) and integral Liquid Water Content (LWC) microwave radiometric retrieval from satellites by means of dual-frequency method (inverse problem). The errors under consideration may arise due to the non-linearity of brightness temperature level on true liquid water and effective cloud temperature dependencies and due to neglecting the spatial distribution of cumulus clouds in the satellite microwave radiometer antenna field-of-view (FOV). Comprehensive evaluation of these errors requires sequential forward and then inverse problem solving in different variations for numerous of possible cloudy atmosphere states (3D), satellite locations and observation angles, various FOV sizes, used frequency channel pairs, etc. It is clear that bruteforce approach would be purblind and short-sighted here. On the other hand, it turns out that cumuli are not fully randomly distributed in the atmosphere, but their number density and power distributions are subject to quite understandable statistics (see, e.g. Plank, 1969).
In this dataset, we constrain ourselfs to considering standard atmosphere 3D-cells (i.e. altitude profiles of thermodynamic temperature, pressure and air humidity are standard), but additionally filled with cumuli distributed according to several represantative cases taken from (Plank, 1969), see table no. 2. A number of modifications for these cases are also considered. Herewith, the shape of clouds is assumed to be cylindrical. The size of the cell is set to 50x50x10 km (Ox x Oy x Oz). An introduced computational grid has 300x300x100 nodes. A smooth water surface with temperature of 15°C and zero salinity is considered as an underlying one. An observation angle is taken to be 0° from zenith. Satellite radiometer antenna FOV sizes are 1x1 and 60x60 nodes. The altitude profile of liquid water inside a cloud is approximated according to (Mazin, 1983). It is supposed that liquid water is zero outside the clouds. The effective cloud temperature parameter used in the course of TWV and LWC retrieval is chosen constant and equal to 0°C. All the other parameters necessary while retrieval process are either known in advance or determined from the results of solving the forward problem in case of clear sky. The retrieval is carried out for three frequency pairs: 22.2 and 27.2 GHz, 22.2 and 36 GHz, 22.2 and 89 GHz. The consideration of such a limited number of cases already allows one to draw conclusions about the nature of the relationship between systematic errors of moisture content parameters retrieval, the Plank model parameters, and the size of satellite radiometer antenna field of view.
The dataset is generated by this script, using armrad framework (Python + TensorFlow GPU).
Please download 7z-archive and extract it.
Load data into RAM using dill library
import dill
with open('post_data_theta0_kernel60_all.bin', 'rb') as dump:
obj = dill.load(dump)
The code below will apparently make it easier to operate with the data structure
import numpy as np
class Data:
def __init__(self, column_names, data):
self.names = column_names
self.data = data
n = {}
for key, value in enumerate(self.names):
n[value] = key
self.n = n
def get(self, *args) -> np.ndarray:
out = []
for arg in args:
out.append(self.data[:, self.n[arg]])
out = np.asarray(out)
if len(args) == 1:
return out[0]
return out
def dist(self, prefix: str) -> 'Data':
cond = np.asarray([str(distr_name).find(prefix) + 1
for distr_name in self.get('distr_name')], dtype=bool)
return Data(column_names=self.names, data=self.data[cond])
def select(self, **kwargs) -> 'Data':
cond = np.asarray([True for _ in range(len(self.data))])
for key, value in kwargs.items():
d = self.get(str(key)).astype(type(value))
if not isinstance(value, str):
cond = np.isclose(d, value) & cond
else:
cond = (d == value) & cond
return Data(column_names=self.names, data=self.data[cond])
def __add__(self, data):
if not data:
return Data(column_names=self.names, data=self.data)
return Data(column_names=self.names, data=np.vstack((self.data, data.data)))
def means(arr) -> np.ndarray:
return np.asarray([val.mean for val in arr])
def mins(arr) -> np.ndarray:
return np.asarray([val.min for val in arr])
def maxs(arr) -> np.ndarray:
return np.asarray([val.max for val in arr])
def bind(*arrays):
return tuple(np.asarray(sorted(list(zip(*arrays)), key=lambda e: e[0])).T)
data = Data(column_names=obj[0], data=obj[1:])
See also the attached .ipynb script.
More from this Author

Dataset Files
- post_data_theta0_kernel60_all.bin dataset.7z (14.58 MB)
- script.ipynb script.7z (140.28 kB)





