Datasets
Standard Dataset
A Comprehensive Dataset for Deep Learning-Based Monitoring and Analysis in Real Process Control Networks
- Citation Author(s):
-
EddisonJaggernauth
 The University of the West Indies -Department of Electrical and Computer Engineering
The University of the West Indies -Department of Electrical and Computer Engineering - Submitted by:
- Eddison Jaggernauth
- Last updated:
- Sat, 09/21/2024 - 09:24
- DOI:
- 10.21227/ycks-8829
- Data Format:
- Research Article Link:
- Links:
- License:
 992 Views
992 Views- Categories:
- Keywords:
Abstract
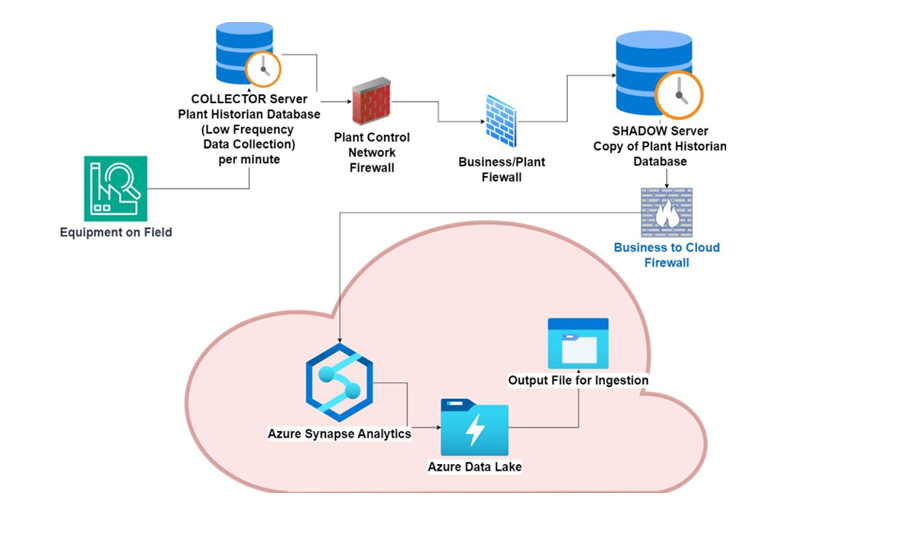
This article presents a dataset collected from a real process control network (PCN) to facilitate deep-learning-based anomaly detection and analysis in industrial settings. The dataset aims to provide a realistic environment for researchers to develop, test, and benchmark anomaly detection models without the risk associated with experimenting on live systems. It reflects raw process data from a gas processing plant, offering coverage of critical parameters vital for system performance, safety, and process optimization.
Each entry in the dataset contains three primary fields viz.
TAGNAME: Identifier for each sensor.
TIMESTAMP: Date and time of the reading, recorded with high precision.
VALUE: Numeric reading from the sensor.
Process plant data for key control points (Tags) are captured. The dataset also includes a summary of historical data for the different tags (FIC1.PV, FIC2.PV, LIC3.PV, LT_4.PV, LT_5.PV, PIC8.PV, PIT_6.PV, PIT_7.PV), each with statistical measures over a period from December 31, 2014, to November 29, 2023. Each tag's criteria for out-of-range classification is also included.
The data may be used in various scenarios including:
Sensor Analysis: Users can analyze the data for each sensor individually to understand its behavior and trends over the observed period. This could include studying the mean, standard deviation, and other statistical measures for each sensor.
Time Series Analysis: Given the timestamp data, users can perform time series analysis to identify patterns, anomalies, or regularities in sensor readings over time.
Comparative Analysis: Comparing data across different sensors might reveal correlations or dependencies among different sensor readings.
Event Detection: Users might be interested in identifying specific events or changes in trends, which can be done by looking for significant deviations in the sensor readings over time.
Users should be aware of any potential outliers or anomalies in the data, which might affect analyses. It is recommended to conduct a thorough data cleaning and preprocessing step before any in-depth analysis.
Please see Data Descriptor paper for details.
Dataset Files
- Process Control Network Data based on production Gas Plant.zip (261.66 MB)
- Sample code - Deep-Learning-Based Monitoring and Analysis in Real Process Control Networks (DLMAPCN).txt (7.77 kB)
Documentation





