English-Bangla corpus
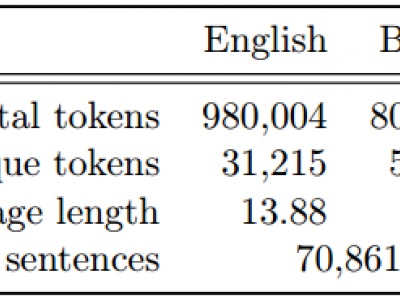
This dataset contains 70,861 English-Bangla sentence pairs and more than 0.8 million tokens in each side.
- Categories:
 3688 Views
3688 ViewsThis dataset contains 70,861 English-Bangla sentence pairs and more than 0.8 million tokens in each side.
3688 Views