Artificial Intelligence

Laboratory experiments are fundamental to science education, yet resource constraints often limit students’ access to hands-on learning experiences. While object detection technology offers promising solutions for automated material identification and assistance, existing datasets like CABD (21 classes) and Chemical Experiment Image Dataset (7 classes) are limited in scope. We present two comprehensive datasets for laboratory material detection: a Chemistry dataset comprising 1,191 images across 60 classes and a Physics dataset containing 1,749 images across 76 classes.
- Categories:
 21 Views
21 Views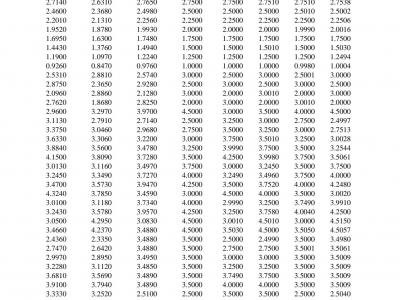
This is the sample data from a switched-capacitor single-input multiple-output (SC-SIMO) converter, which can be utilized to train an artificial neural network (ANN) model. In the dataset, the current references IL3ref, IL2ref, IL1ref, and IL0ref are recorded and applied to the switched-capacitor single-input multiple-output (SC-SIMO) converter, and the introduced inductor currents IL3, IL2, IL1, and IL0 are recorded. During the ANN training process, the inductor currents are considered as the inductor currents references, which are the four inputs of the ANN model.
- Categories:
193 Views
Ensemble clustering, which integrates multiple base clusterings to enhance robustness and accuracy, is commonly evaluated on over 10 benchmark datasets. These include 6 synthetic datasets (e.g., 3MC,atom,Chainlink,Flame,Jain,wingnut) designed to test algorithms on nonlinear separability and density variations.
- Categories:
16 Views
The Forbes 2022 Billionaires List dataset contains information about the world's wealthiest individuals, including their net worth, industry, country, and key business ventures. The dataset provides structured details such as rankings, company associations, and financial status, making it useful for various NLP tasks like table-to-text generation, entity recognition, and financial analysis.
- Categories:
47 Views
To establish a versatile RSFM adaptable to diverse tasks, RingMoE requires a comprehensive and diverse pre-training dataset that accounts for significant variations in imaging modalities, spatial resolutions, temporal dynamics, geographic regions, and scene complexities. To meet this challenge, we curate RingMOSS, a large-scale multi-modal RS dataset comprising 400 million images from nine satellite platforms, covering a broad spectrum of Earth observation scenarios.
- Categories:
25 Views
This dataset contains texture maps, flow field data, and aerodynamic pressure data on the surface of five different vehicle profiles under specific flight conditions, and is suitable for research in aerospace engineering, hydrodynamics, and related fields. The dataset covers the altitude range from 3000 to 4000 meters and the Mach number range from 2.0 to 2.75.
- Categories:
245 Views
This wind speed dataset is voluntarily made public by me, with the aim of supporting academic research, data analysis, and further exploration in related fields. The dataset strictly adheres to relevant safety protocols, ensuring that all data usage and dissemination comply with safety requirements and respect applicable laws and regulations. By making this dataset public, I hope to provide a reliable resource for the academic community, researchers, and other institutions in need, to foster more research and technological development based on wind speed.
- Categories:
10 Views
This dataset integrates textual, financial, and macroeconomic indicators to support research on bank failure prediction and financial distress forecasting in Vietnam. It includes financial news from the BKAI News Corpus Dataset (2009–2023) and financial crisis data from "A Dataset for the Vietnamese Banking System (2002–2021)" (Tu Le et al., 2022), covering crisis-related events such as restructuring, special control, mergers, and acquisitions.
- Categories:
52 Views
The Semantic Highlight Mask Dataset holds significant importance in the field of computer vision, particularly for tasks such as object detection, image segmentation, and scene understanding. This paper proposes a novel Semantic Highlight Mask Dataset designed to support high-precision semantic segmentation and emphasize key regions in images. The dataset encompasses a diverse range of image categories, with finely annotated highlight masks assigning semantic labels and saliency weights to each pixel.
- Categories:
10 Views
The Semantic Highlight Mask Dataset holds significant importance in the field of computer vision, particularly for tasks such as object detection, image segmentation, and scene understanding. This paper proposes a novel Semantic Highlight Mask Dataset designed to support high-precision semantic segmentation and emphasize key regions in images. The dataset encompasses a diverse range of image categories, with finely annotated highlight masks assigning semantic labels and saliency weights to each pixel.
- Categories:
6 Views