Artificial Intelligence
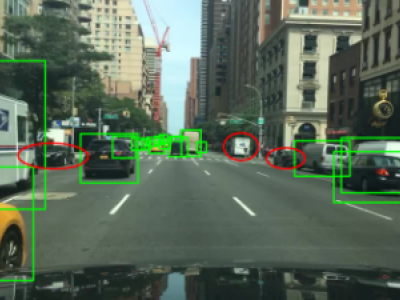
To address common issues in intelligent driving, such as small object missed detection, false detection, and edge segmentation errors, this paper optimizes the YOLOP (You Only Look Once for Panoptic Driving Perception) network and proposes a multi-task perception algorithm based on a MKHA (Multi-Kernel Hybrid Attention) mechanism, named MKHA-YOLOP.
- Categories:
 132 Views
132 Views
BoardData is constructed from development board data provided by ST. These development boards are primarily utilized for function demonstration and platform development of STM32 series microcontrollers. They incorporate a suite of common sub-circuit modules for electronic devices, including interface modules, digital-to-analog and analog-to-digital converter modules, memory modules, comparators, touch modules, display modules, switch arrays, among others. Consequently, these boards exhibit a high degree of consistency with real PCB circuits.
- Categories:
35 Views
Partial dataset of CHVM-1K dataset for illustration purposes.
{
"question": "What stages can be divided into in the development history of ancient Chinese bronzes? Why?",
"answer": "The development history of ancient Chinese bronzes can be divided into several stages: Xia (2100-1600 BCE), Shang (1600-1046 BCE), Early Western Zhou (1046-771 BCE), Middle Western Zhou (771-720 BCE), Late Western Zhou (720-256 BCE), and Eastern Zhou (256-256 BCE). These stages are marked by technological advancements, stylistic evolution, and cultural significance.",
- Categories:
16 Views
- Categories:
38 Views
To train and evaluate our enhancement framework, SS2DS, we establish a benchmark for the spike stream enhancement. The benchmark includes a synthetic spike stream enhancement dataset, SED, and a real sparse spike streams dataset for driving scenarios, SSDD. The SED dataset consists of 125 randomly high-speed dynamic scenes where 100 scenes are as the training set, named SED$_{tr}$, and 25 scenes are as the test set with ground truth, named SED$_{te}$. This dataset consists of 24 driving scenes and each scenario records a spike stream with 20,000 frames.
- Categories:
25 Views
- Categories:
53 Views
Recently, machine learning models have seen considerable growth in size and popularity, lead-
ing to concerns regarding dataset privacy, especially around sensitive data containing personal information.
To address data extrapolation from model weights, various privacy frameworks ensure that the outputs of
machine learning models do not reveal their training data. However, this often results in diminished model
performance due to the necessary addition of noise to model weights. By enhancing models’ resistance to
- Categories:
27 Views
The demand for intelligent automation in factories has been steadily increasing. While traditional robotic arms perform simple automated tasks, deep reinforcement learning enables them to execute more complex operations. However, deep reinforcement learning in the field of robotics often encounters challenging learning tasks, especially in three-dimensional and continuous environments where obtaining rewards becomes sparse. To address this issue, this article proposes the Hindsight Proximal Policy Optimization (HPPO) method for intelligent robotic control.
- Categories:
23 Views
This collection includes multiple short text classification datasets designed for various natural language processing tasks. It contains several topic classification datasets, such as AG'News, Snippets, and TMNNews, which cover a wide range of topics and domains to evaluate the effectiveness of classification models. Additionally, the collection includes a binary sentiment classification dataset, such as Twitter, aimed at determining positive or negative sentiment in text.
- Categories:
19 Views
This collection includes multiple short text classification datasets designed for various natural language processing tasks. It contains several topic classification datasets, such as AG'News, Snippets, and TMNNews, which cover a wide range of topics and domains to evaluate the effectiveness of classification models. Additionally, the collection includes a binary sentiment classification dataset, such as Twitter, aimed at determining positive or negative sentiment in text.
- Categories:
36 Views