DCASE2016: Sound event detection in real life audio
- Submission Dates:
-
to
- Citation Author(s):
- Submitted by:
- Alexander Outman
- Last updated:
- DOI:
- 10.21227/H2Z595
- Data Format:
- Links:
- Categories:
- Keywords:
Abstract
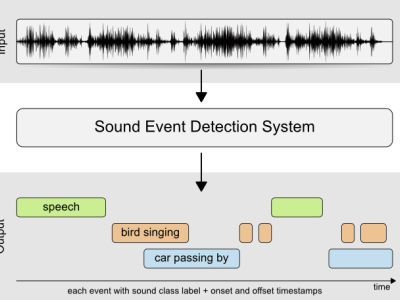
This task evaluates performance of the sound event detection systems in multisource conditions similar to our everyday life, where the sound sources are rarely heard in isolation. Contrary to task 2, there is no control over the number of overlapping sound events at each time, not in the training nor in the testing audio data.
Audio dataset
TUT Sound events 2016 dataset will be used for task 3. Audio in the dataset is a subset of TUT Acoustic scenes 2016dataset (used for task 1). The TUT Sound events 2016 dataset consisting of recordings from two acoustic scenes:
- Home (indoor)
- Residential area (outdoor).
These acoustic scenes were selected to represent common environments of interest in applications for safety and surveillance (outside home) and human activity monitoring or home surveillance.
The dataset was collected in Finland by Tampere University of Technology between 06/2015 - 01/2016. The data collection has received funding from the European Research Council.
Recording and annotation procedure
The recordings were captured each in a different location: different streets, different homes. For each recording location, 3-5 minute long audio recording was captured. The equipment used for recording consists of a binaural Soundman OKM II Klassik/studio A3 electret in-ear microphone and a Roland Edirol R-09 wave recorder using 44.1 kHz sampling rate and 24 bit resolution. For audio material recorded in private places, written consent was obtained from all people involved.
Individual sound events in each recording were annotated by two research assistants using freely chosen labels for sounds. Nouns were used to characterize each sound source, and verbs the sound production mechanism, whenever this was possible. Annotators were trained first on few example recordings. They were instructed to annotate all audible sound events, decide the start time and end time of the sounds as they see fit, and choose event labels freely. This resulted in a large set of raw labels. There was no verification of the annotations and no evaluation of annotator inter-annotator agreement due to the high level of subjectivity inherent to the problem.
Target sound event classes were selected based on the frequency of the obtained labels, to ensure that the selected sounds are common for an acoustic scene, and there are sufficient examples for learning acoustic models. Mapping of the raw labels was performed, merging for example "car engine running" to "engine running", and grouping various impact sounds with only verb description such as "banging", "clacking" into "object impact".
Selected sound event classes:
Home
- (object) Rustling
- (object) Snapping
- Cupboard
- Cutlery
- Dishes
- Drawer
- Glass jingling
- Object impact
- People walking
- Washing dishes
- Water tap running
Residential area
- (object) Banging
- Bird singing
- Car passing by
- Children shouting
- People speaking
- People walking
- Wind blowing
For residential area, the sound event classes are mostly related to concrete physical sound sources - bird singing, car passing by. Home scenes are dominated by abstract object impact sounds, besides some more well defined sound events (still impact) like dishes, cutlery, etc.
Instructions:
Challenge setup
TUT Sound events 2016 dataset consists of two subsets: development dataset and evaluation dataset. Partitioning of data into these subsets was done based on the amount of examples available for each sound event class, while also taking into account recording location. Ideally the subsets should have the same amount of data for each class, or at least the same relative amount, such as a 70-30% split. Because the event instances belonging to different classes are distributed unevenly within the recordings, the partitioning of individual classes can be controlled only to a certain extent.
The split condition was relaxed from 70-30%. For home, 40-80% of instances of each class were selected into the development set. For residential area, 60-80% of instances of each class were selected into the development set.
Participants are not allowed to use external data for system development. Manipulation of provided data is allowed. Acoustic scene label can be used as external information in the detection (acoustic scene-dependent sound event detection system).
In publications using the datasets, cite as:
Annamaria Mesaros, Toni Heittola, and Tuomas Virtanen, Tut database for acoustic scene classification and sound event detection, In 24rd European Signal Processing Conference 2016 (EUSIPCO 2016). Budapest, Hungary, 2016. PDF
Cross-validation with development dataset
A cross-validation setup is provided in order to make results reported with this dataset uniform. The setup consists of four folds, so that each recording is used exactly once as test data. While creating the cross-validation folds, the only condition imposed was that the test subset does not contain classes unavailable in training subset. The folds are provided with the dataset in the directory evaluation_setup.
Evaluation dataset
Evaluation dataset without ground truth will be released shortly before the submission deadline. Full ground truth meta data for it will be published after the DCASE 2016 challenge.
Submission
Detailed information for the challenge submission can found from submission page.
One should submit single text-file (in CSV format) per evaluated acoustic scene (home and residential area), each file containing detected sound event from each audio file. Events can be in any order. Format:
[filename (string)][tab][event onset time in seconds (float)][tab][event offset time in seconds (float)][tab][event label (string)]
Evaluation
Total error rate (ER) is the main metric for this task. Error rate will be evaluated in one-second segments over the entire test set. Ranking of submitted systems will be done using this metric. Additionally, other metrics will be calculated.
Detailed description of metrics can be found here.
Code for evaluation is available with the baseline system:
- Python implementation
from src.evaluation import DCASE2016_EventDetection_SegmentBasedMetricsandfrom src.evaluation import DCASE2016_EventDetection_EventBasedMetrics. - Matlab implementation, use classes
src/evaluation/DCASE2016_EventDetection_SegmentBasedMetrics.mandsrc/evaluation/DCASE2016_EventDetection_EventBasedMetrics.m.
sed_eval - Evaluation toolbox for Sound Event Detection
sed_eval contains same metrics as baseline system, and they are tested to give same values. Use parameters time_resolution=1 and t_collar=0.250 to align it with the baseline system results.








