File Fragment Type (FFT) - 75 Dataset
- Citation Author(s):
-
Govind Mittal (New York University)Pawel Korus (New York University)Nasir Memon (New York University)
- Submitted by:
- Pawel Korus
- Last updated:
- DOI:
- 10.21227/kfxw-8084
- Data Format:
- Research Article Link:
- Links:
 3679 views
3679 views
- Categories:
- Keywords:
Abstract
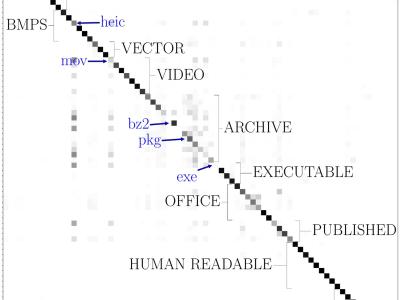
This FFT-75 dataset contains randomly sampled, potentially overlapping file fragments from 75 popular file types (see details below). It is the most diverse and balanced dataset available to the best of our knowledge. The dataset is labeled with class IDs and is ready for training supervised machine learning models. We distinguish 6 different scenarios with different granularity and provide variants with 512 and 4096-byte blocks. In each case, we sampled a balanced dataset and split the data as follows: 80% for training, 10% for testing and 10% for validation.
Instructions:
See documentation (readme.md).
-
Wei Lim
Wed, 09/01/2021 - 03:28
Permalink
thanks!
Li Hui
Wed, 01/12/2022 - 06:54
Permalink
Dataset Files
- Scenario #1 (4096-byte blocks) (Size: 24.18 GB)
- Scenario #2 (4096-byte blocks) (Size: 6.08 GB)
- Scenario #3 (4096-byte blocks) (Size: 8.25 GB)
- Scenario #4 (4096-byte blocks) (Size: 3.72 GB)
- Scenario #5 (4096-byte blocks) (Size: 3.67 GB)
- Scenario #6 (4096-byte blocks) (Size: 3.77 GB)
- Scenario #1 (512-byte blocks) (Size: 3.18 GB)
- Scenario #2 (512-byte blocks) (Size: 825.67 MB)
- Scenario #3 (512-byte blocks) (Size: 1.06 GB)
- Scenario #4 (512-byte blocks) (Size: 490.66 MB)
- Scenario #5 (512-byte blocks) (Size: 484.36 MB)
- Scenario #6 (512-byte blocks) (Size: 490.54 MB)
- Human-readable labels (Size: 902 bytes)
- Use-case hierarchy (Size: 1.09 KB)
LOGIN TO ACCESS DATASET FILES
Open Access dataset files are accessible to all logged in users. Don't have a login? Create a
free IEEE account. IEEE Membership is not required.