Datasets
Open Access
Deduplication Index for Big Code Datasets
- Citation Author(s):
-
MiltiadisAllamanis
 Microsoft Research
Microsoft Research - Submitted by:
- Miltiadis Allamanis
- Last updated:
- Thu, 06/27/2019 - 11:47
- DOI:
- 10.21227/e9eb-ma51
- Data Format:
- Links:
- License:
- Creative Commons Attribution
 679 Views
679 Views- Categories:
- Keywords:
Abstract
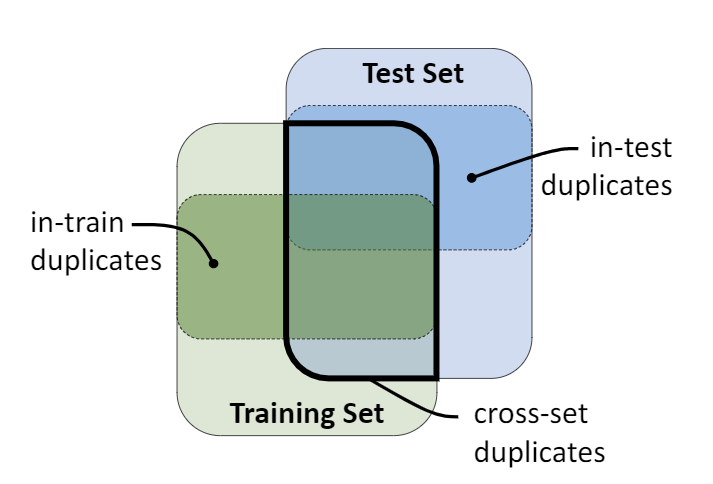
Code duplicates in large code corpora have adverse effects on the evaluation and use of machine learning models that rely on them. Most existing corpora suffer from this problem to some extent. This dataset contains a "duplication" index for some of the existing corpora in Big Code research. The method for collecting this dataset is described in "The Adverse Effects of Code Duplication in Machine Learning Models of Code" by Allamanis [ArXiV, to appear in SPLASH 2019].
For each of the existing datasets, a single .json file is provided. Each JSON file has the following format:
[ duplicate_group_1, duplicate_group_2, ...]
where each duplicate group is a list of filenames of that dataset that are near duplicates.
For the corpora that were given as a single file (e.g. Hashimoto et al.) the line number of the original record is given.
Dataset Files
 duplication_index.zip (11.80 MB)
duplication_index.zip (11.80 MB)
Open Access dataset files are accessible to all logged in users. Don't have a login? Create a free IEEE account. IEEE Membership is not required.





