Datasets
Standard Dataset
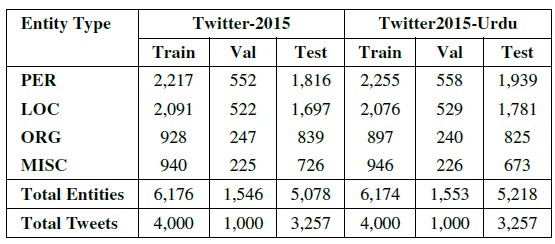
Twitter2015-Urdu
- Citation Author(s):
- Submitted by:
- Hussain Ahmad
- Last updated:
- Wed, 01/15/2025 - 22:13
- DOI:
- 10.21227/3y9j-7j09
- Data Format:
- License:
 25 Views
25 ViewsAbstract
<p>The <strong>Twitter2015-Urdu Dataset</strong> is a multimodal resource designed to advance Multimodal Named Entity Recognition (MNER) research in Urdu, a low-resource language. It adapts the widely used Twitter2015 English dataset with culturally grounded annotations tailored to Urdu's unique linguistic complexities. Featuring a balanced split across training, validation, and test sets, this dataset addresses the limitations of existing resources like CRULP, UCREL, and WikiDiverse, making it a critical tool for advancing Urdu-specific MNER research and multimodal applications.</p>
The Twitter2015-Urdu Dataset is a multimodal resource designed for Multimodal Named Entity Recognition (MNER) research. It consists of 8,257 annotated text-image pairs, divided into training, validation, and test sets.
Using the Dataset:
-
Download the Dataset Files:
- The dataset is divided into structured files for training, validation, and testing.
- Each file contains text, corresponding images, and named entity annotations.
-
Dataset Structure:
- Each entry includes:
- Text: An Urdu text snippet (UTF-8 encoded).
- Image: Associated visual content (JPG/PNG format).
- Annotations: Named entity labels categorized as:
- PER (Person)
- LOC (Location)
- ORG (Organization)
- MISC (Miscellaneous)
- Each entry includes:
-
Preprocessing:
- The text is tokenized using the Urduhack library. If further tokenization or preprocessing is needed, ensure Urdu language compatibility.
-
Annotations:
- Annotations align with the linguistic and cultural nuances of Urdu. Refer to the annotation guidelines in the documentation for consistency.
-
Multimodal Research:
- Combine the text and image data for multimodal experiments using your preferred deep learning or NLP frameworks.
Documentation
| Attachment | Size |
|---|---|
| 998 bytes |





