Rich Text to Video Generation: Towards Region-Controllable Synthesis with Spatio-Temporal Coherence

- Citation Author(s):
-
Shuang Wang
- Submitted by:
- shuang wang
- Last updated:
- DOI:
- 10.21227/kpkh-vj98
 7 views
7 views
- Categories:
- Keywords:
Abstract
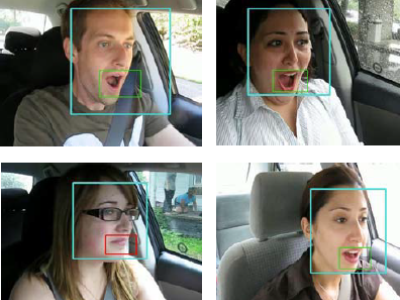
Existing plain text-based video generation methods have limited expressiveness and struggle to provide detailed descriptions and precise control of attributes. To address this, we introduce rich text for video generation, which faces two main challenges: coherent control between frames and consistency among rich text attributes, plain text, and control regions. We propose a solution: utilizing first-frame noise sampling and motion pattern prediction to ensure frame consistency; determining control regions by extracting spatio-temporal attention maps through plain text prompts and denoising process; employing spatio-temporal region diffusion and dynamic feature maps injection to maintain content consistency of plain text and rich text attributes. Extensive experimental results demonstrate that our method can generate high-quality videos using rich text on a single GPU without additional training, providing a more flexible and precise control method for video generation tasks.
Instructions:
This includes experimental data from my thesis and additional generated data.