Indian Sign Language Skeletal-point NumPy array using MediaPipe
- Citation Author(s):
-
Jans JohnsonJisha JosephMaris RejiMegha George
- Submitted by:
- Jisha Joseph
- Last updated:
- DOI:
- 10.21227/6emn-2r12
- Data Format:
- Links:
 1654 views
1654 views
- Categories:
- Keywords:
Abstract
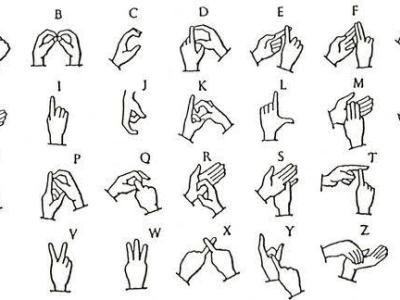
The dataset consists of NumPy arrays for each alphabet in Indian Sign Language, excluding 'R'. The NumPy arrays denote the (x,y,z) coordinates of the skeletal points of the left and right hand (21 skeletal points each) for each alphabet. Each alphabet has 120 sequences, split into 30 frames each, giving 3600 .np files per alphabet, using MediaPipe.
The dataset is created on the basis of skeletal-point action recognition and key-point collection.
Instructions:
The NumPy arrays can be used as input data into various ML models to train it in recognizing alphabets in Indian Sign Language







really helpful
really helpful for my project
helpful