First Name
Prarthana
Last Name
Dutta
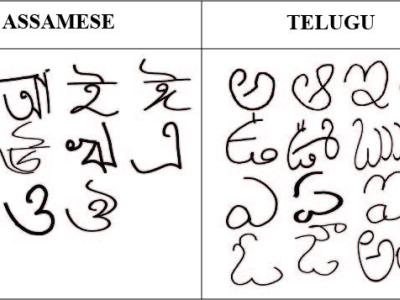
Various datasets for character recognition have been collected, explored, and utilized for numerous OCR tasks. India, being a linguistically diverse country, has seen extensive OCR research, although some regional languages, such as Assamese and Telugu, have been less explored due to the unavailability of suitable datasets. To address this gap, the AsTel dataset has been developed, comprising Assamese and Telugu handwritten characters collected offline using a paint mobile application.

This is a dataset comprising of handwritten text in Assamese and Telugu. Individuals from Assam and Andhra Pradesh were approached to give the handwritten text samples on a plain paper. These texts were captured using a mobile camera and 300 dpi resolution. These text images can be used for language recognition as well as segmentation at different levels such as line, word and character. Our dataset consisted of 200 samples of Assamese and 222 samples of Telugu handwritten text. Each text consist of 5-10 text lines of essay and short stories.

This dataset comes up as a benchmark dataset for machines to automatically recognizing the handwritten assamese digists (numerals) by extracting useful features by analyzing the structure. The Assamese language comprises of a total of 10 digits from 0 to 9. We have collected a total of 516 handwritten digits from 52 native assamese people irrespective of their age (12-86 years), gender, educational background etc. The digits are captured in .jpeg format using a paint mobile application developed by us which automatically saves the images in the internal storage of the mobile.