Other

Supplementary material for article "An Efficient Meta-Heuristic for Multi-objective Flexible Job Shop Inverse Scheduling Problem"
- Categories:
 3294 Views
3294 Views
A continuous finite-time control scheme is introduced for bilateral teleoperation systems with asymmetric timevarying delays. Specifically, a non-smooth controller with fractional power based on the homogeneous method is developed to guarantee that the trajectory tracking error between the master and the slave converges to zero in a finite period of time.
- Categories:
135 Views
A continuous finite-time control scheme is introduced for bilateral teleoperation systems with asymmetric timevarying delays. Specifically, a non-smooth controller with fractional power based on the homogeneous method is developed to guarantee that the trajectory tracking error between the master and the slave converges to zero in a finite period of time.
- Categories:
117 Views
This repository contains job workload data for the paper titled 'eBlocBroker: A Blockchain Based Autonomous Computational Resource Broker'. Dataset includes job workload data for the tests (1-5) and the output data which are described in Table 1. Logs of submitted jobs, their block transaction hashes and Slurm job submission information which are output by the Driver program are provided.
- Categories:
289 Views
This is a model of artificial intelligence architecture developed using the
technique of targeting and assembling various components (as needed) together
to get artificial intelligence with characteristics similar to human intelligence.
This model represents the general form, the strategy, and the mechanism of
manufacturing an artificial intelligence device and the fact that based on what
structure it can turn into artificial intelligence. One of the important features of
- Categories:
385 Views
Accessibility and Activity-Centered Design for ICT Users: ACCESIBILITIC Ontology
ABSTRACT
- Categories:
484 Views
This research examined the electrical characteristics
of a conventional junctionless silicon-on-insulator (SOI-JL) and a
SOI hybrid P/N fin channel JL thin film transistor (SOI-H-JL)
using a simulation with gate lengths from 60 nm to 10 nm. The
interface location of the SOI-H-JL has a depletion region of a
parallel channel, which influences the effective thickness of the
channel. The threshold voltage can be adjusted by changing the
concentration of the substrate. Better electrical characteristics
- Categories:
95 Views
This dataset is for validate and evaluate English-Bangla machine translation systems.
- Categories:
2199 Views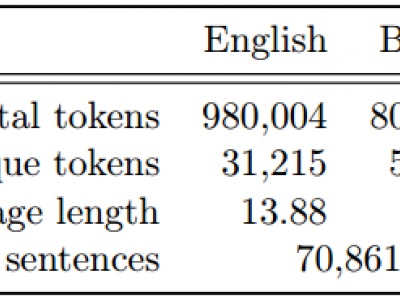
This dataset contains 70,861 English-Bangla sentence pairs and more than 0.8 million tokens in each side.
- Categories:
3685 Views
The file is for an improved compact SPICE model validated for the terahertz frequency range in a large dynamic range. The model validation
was done by comparing the simulation results with the analytical THz detection theory and with the measured data for the 130 nm InGaAs/AlGaAs HFETs. The modeling results are in good agreement with the analytical THz detection theory and with the measured sub-THz response dependence on the bias, power, and polarization. It
- Categories:
205 Views