SQLR: Short Term Memory Q-Learning for Elastic Provisioning
- Citation Author(s):
-
Constantine Ayimba
- Submitted by:
- Constantine Ayimba
- Last updated:
- DOI:
- 10.21227/kr5e-bd82
- Data Format:
 93 views
93 views
- Categories:
- Keywords:
Abstract
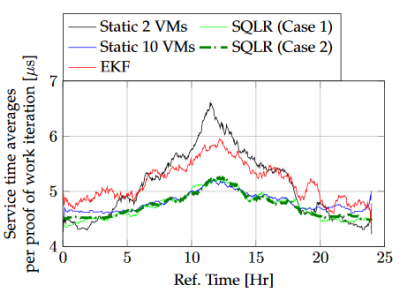
Service times for the scaling schemes compared in this paper with the administrative switching overheads averaged out
Instructions:
1. The end time for each of the requests is obtained by adding service time (field 3) to field 1 to obtain a timestamp for the end of the proof of work run (field 4)
2. Field 3 is divided by the number of iterations (field 2) to obtain the time per proof of work iteration (field 5)
3. For each case, the corresponding file should then be sorted by the field 1 timestamp
4. Time bins of 120 seconds from the corresponding initial timestamp per file - detailed in the README - should be created then all times per iteration that start and end within the two timestamps (field 1 and field 4) should be averaged and the result given a timestamp that is the midpoint of the corresponding time bin
5. A moving average filter is applied to these averages with a window of 30 samples, the reference time in hours is obtained by subtracting the initial timestamp per file - as given in the README - from the bin timestamp and dividing the result by 3,600,000 (the number of milliseconds in an hour)