PowerWatch State Machine Experiments
- Citation Author(s):
-
Cengiz Kaygusuz (Florida International University)
- Submitted by:
- Cengiz Kaygusuz
- Last updated:
- DOI:
- 10.21227/qp54-s651
- Data Format:
 281 views
281 views
- Categories:
- Keywords:
Abstract
This dataset details the state machine based experiments of PowerWatch.
Instructions:
PowerWatch Experiment Summaries
This dataset summarizes the experiments done for the PowerWatch paper. The accompanying code will be
shared after the paper is published.
There are 2 files:
* expres.csv: Each entry in this file represents the summary with respect to a unique state machine, represented by
the field "state_machine_id".
* runres.csv: For each state machine, a total of 45 runs are conducted, each individual runs are represented by
an entry.
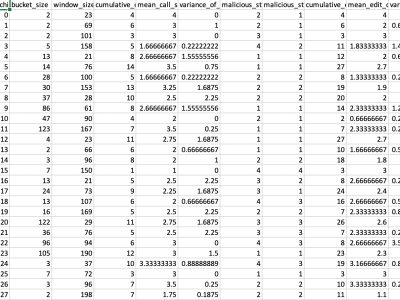
The fields in "expres.csv" are explained as follows.
* state_machine_id: A number uniquely identifies an experiment. The ID was also used as a random seed.
The naming here is, unfortunately, confusing.
* bucket_size: Chosen bucket size.
* window_size: Chosen window size.
Next 12 fields represent the "complexity" of the machine with respect to call lists they emit.
In each experiment, two machines were run: benign and malicious. The difference between those are that, in the
malicious machine, there is one more state emitting an unique call list.
* cumulative_call_size_benign: Sum of the number of call lists emitted by benign states.
* mean_call_size_benign: Mean of the call lists emitted by benign states.
* variance_call_size_benign: Variance of the call lists emitted by benign states.
* malicious_state_call_size: Number of calls emitted by the malicious state.
* malicious_state_vocabulary_size: Number of different calls emitted by the malicious state.
* cumulative_edit_distance_every_state: The edit distance between every state. Represents
how the individual computing states vary from each other.
* mean_edit_distance_every_state: Mean of the edit distance computed between every state.
* variance_of_edit_distance_every_state: Variance of the edit distances computed between every state.
* cumulative_edit_distance_good_bad: Total edit distance computed between every benign state and the malicious state.
* mean_edit_distance_good_bad: Mean edit distance computed between every benign state and the maliicous state.
* min_edit_distance_good_bad: Minimum of edit distances computed between every benign state and the maliicous state.
* variance_edit_distance_good_bad: Variance of edit distances computed between every benign state and the maliicous state.
* training_time: Total time required for training the machine learning model.
* prediction_time: Total time required for prediction stage.
* svm_accuracy: Accuracy of a SVM model taking inputs of maximum activity signal per run.
* svm_margin: Unused.
* mean_benign_train_activity_index: Mean activity index, calculated on the training set.
* mean_benign_test_activity_index: Mean activity index, calculated on the data obtained from the benign machine, but not
used for training.
* mean_malicious_activity_index: Mean activity index, calculated on the data obtained from the malicious machine.
Originally, a cascade of max-pooling and convolution mechanism were considered, but we later decided to use a single
convolution step after the prediction stage. The naming of the fields are made with respect to the initial algorithm,
and a little misleading, explained below where necessary:
* state_machine_id: The ID of the associated experiment.
* run_number: The number of the run.
* malicious: If the run contained the malicious state.
* trained_on: If the resulting data used in training.
Remember that the first convolution yields the activity signal. Individual points in the activity signal are
the activity index. Statistics about the activity signal is given in the following fields:
* min_of_first_convolution: Minimum value of the first convolution. This is the minimum activity index in the activity signal.
* max_of_first_convolution: Maximum value of the first convolution. This is the minimum activity index in the activity signal.
* mean_of_first_convolution: Mean value of the first convolution. This is the minimum activity index in the activity signal.
* variance_of_first_convolution: Variance value of the first convolution. This is the minimum activity index in the activity signal.
* prediction_time: Time required to predict data generated in this run.
* reduction_time: Time required during the convolution stage.
* sp_accuracy: Accuracy of the predictor (predicting the next call).
* sp_misclassification: 1 - sp_accuracy.
* activity_index: This value was calculated WRT initial model, and completely useless in the final model. Disregard.