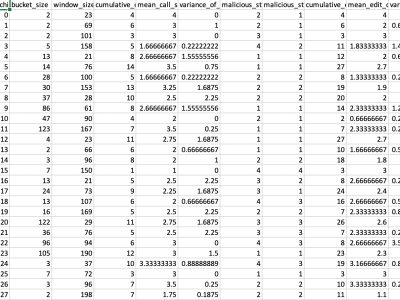
PowerWatch State Machine Experiments This dataset details the state machine based experiments of PowerWatch. Categories: Category Smart Grid Security