Datasets
Standard Dataset
Pavement defect dataset
- Citation Author(s):
- Submitted by:
- Hanqi Tang
- Last updated:
- Wed, 07/31/2024 - 02:02
- DOI:
- 10.21227/52q5-ne18
- Data Format:
- License:
 418 Views
418 Views- Categories:
- Keywords:
Abstract
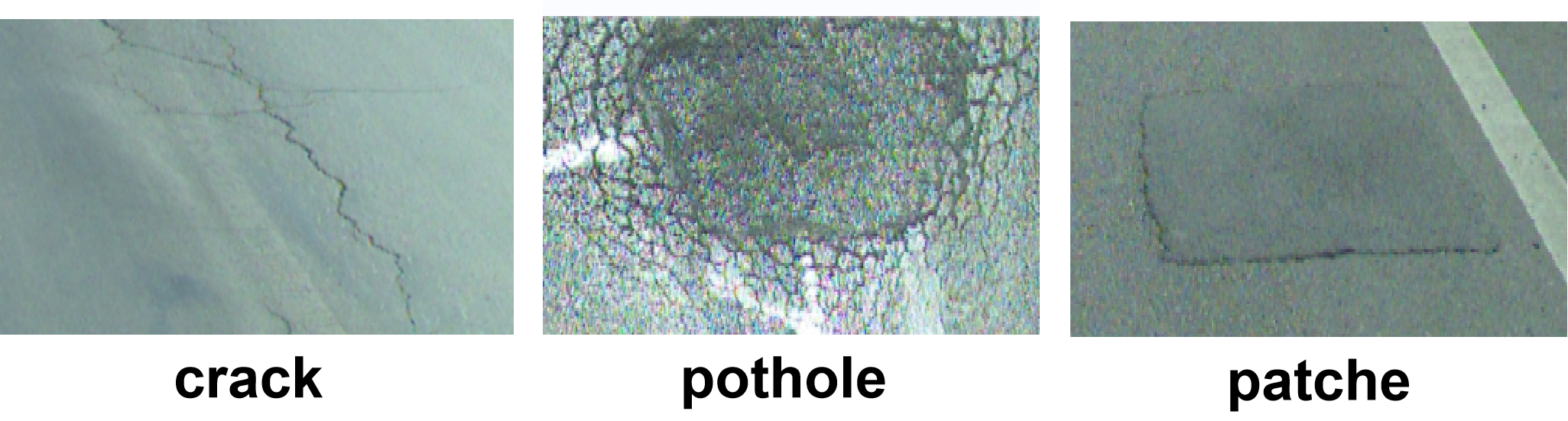
Dataset capturedbyrealtimevehicle-mountedcamerasystem, 600 high-quality images was extracted, 480 as training set, 120 as valid set. The images have a resolution of 1600x1200 and encompass three types of pavement defects, that is, cracks, patches and potholes. Our dataset is in YOLO format, YOLO (You Only Look Once) is a popular object detection framework that uses a single neural network to predict bounding boxes and class probabilities for various objects in an image. The YOLO dataset format typically consists of two main components: the image files and the annotation files. The images are usually stored in a directory, while the annotations are provided in text files with the same name as the corresponding images but with a .txt extension. Each line in an annotation file represents an object and contains information such as the object class, the normalized coordinates of the bounding box (center x, center y, width, height), all relative to the image dimensions. This format allows for efficient training and detection by enabling the neural network to process the entire image in a single forward pass.
<p>The dataset is in YOLO object detection form and the classes is list in classes.txt</p>
Dataset Files
- datasets zip pavement_defect_datasets.zip (873.66 MB)
- readme readme.txt (83 bytes)
Documentation
| Attachment | Size |
|---|---|
| 83 bytes |





