Datasets
Standard Dataset
Mizo Hand Sign Language

- Citation Author(s):
-
Ambeth KumarV.D
 Mizoram University
Mizoram University - Submitted by:
- Ambeth kumar De...
- Last updated:
- Fri, 05/31/2024 - 02:05
- DOI:
- 10.21227/a1we-9a42
- Data Format:
- License:
 182 Views
182 Views- Categories:
- Keywords:
Abstract
In today’s world, deaf and mute person face many problems in their daily life due to miscommunication as well as misunderstanding. These problems have existed since long ago but are ultimately being solved with the introduction of Hand sign language. There exist many different sign languages such as ASL, ISL, etc. But for regional and low-resource languages like Mizo, the state language of Mizoram, spoken by the northeastern people in India, not much research has been done on the advancement of sign language based on the Mizo language. The teaching of sign language was first introduced in the year 1985. The most prevalent problem is that 90% of the school education system has not yet introduced Sign Language in the board of school education as an official language, thus creating a problem for the deaf and mute community. This creates a barrier that isolates them from the norms regarding communication. For this reason, Mizo Sign Language Hand Sign Recognition has been proposed.
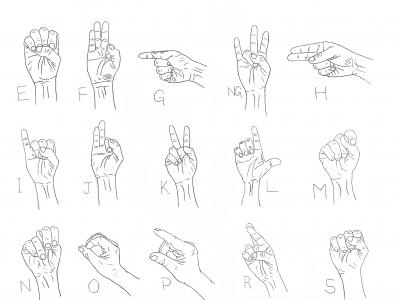
There are no resources or existing datasets readily available, thus signifying the importance of a comprehensive dataset which motivates the reason for creating a new dataset by capturing hand gestures using a high-quality camera called Kinect V2. There are 25 different original images for each of the 25 Mizo hand sign alphabet in the dataset. These images are taken in different periods, such as Morning, Daytime, Evening, and Nighttime to visualize the realistic scenarios faced by the deaf and dumb on a day-to-day basis.
From the original 25 images captured, each alphabet consists of 10 different images captured in different settings, from each of these images 54 augmented/ normalized images are generated, which results in a total of 540 images generated from a single alphabet. The total number of images generated from all alphabets results in 13500 images. Since these images contain higher resolution as well as bigger image sizes, resizing is performed to reduce the size of the images for better utilization of computational resources and computational time.
This Dataset Comprises of a total of 25 files. Each file is named the Alphabets from the Mizo language (A AW B CH D E F G NG H I J K L M N O P R S T Ṭ U V Z) accordingly. Each of these files contains 540 normalized images. These normalized images are generated from 10 original images of one alphabet, captured by Kinect V2 Camera in different periods of time such as, Morning, Afternoon, Evening, And Night-time. The Normalized images are then resized to reduce the image sizes.
More from this Author