Datasets
Standard Dataset
An EMG dataset for Arabic sign language alphabet
- Citation Author(s):
-
AminaBen Haj Amor
 University of TunisOussamaEl GHoulUniversity of TunisMohamedJemniUniversity of Tunis
University of TunisOussamaEl GHoulUniversity of TunisMohamedJemniUniversity of Tunis - Submitted by:
- Oussama El Ghoul
- Last updated:
- Mon, 09/25/2023 - 00:13
- DOI:
- 10.21227/3s5k-1642
- Data Format:
- Research Article Link:
- License:
 767 Views
767 Views- Categories:
- Keywords:
Abstract
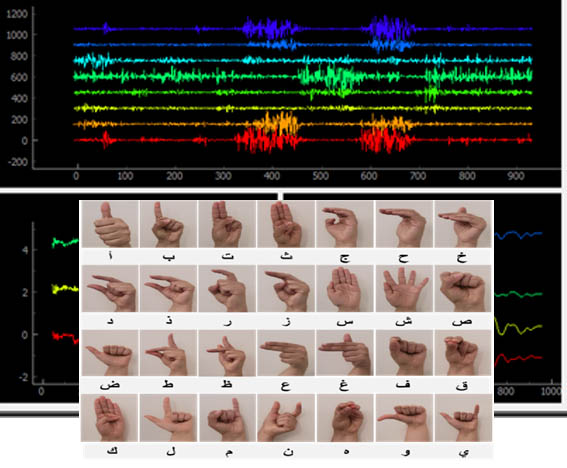
Sign languages are natural, gestural languages that use visual channel to communicate. Deaf people develop them to overcome their inability to communicate orally. Sign language interpreters bridge the gap that deaf people face in society and provide them with an equal opportunity to thrive in all environments. However, Deaf people often struggle to communicate on a daily basis, especially in public service spaces such as hospitals, post offices, and municipal buildings. Therefore, the implementation of a tool for automatic recognition of sign language is essential to allow the autonomy of deaf people. Moreover, it is difficult to provide full-time interpreters to help deaf people in all public services and administrations.
Although surface electromyography (sEMG) provides an important potential technology for the detection of hand gestures, the related research in automatic SL recognition remains limited. To date, most works have focused on the recognition of hand gestures from images, videos, or gloves. The works of BEN HAJ AMOR et al. on EMG signals have shown that these multichannel signals contain rich and detailed information that can be exploited, in particular for the recognition of handshape and for the control prosthesis. Consequently, these successes represent a great step towards the recognition of gestures in sign language.
We build a large database of EMG data, recorded while signing the 28 characters of the Arabic sign language alphabet. This provides a valuable resource for research into how the muscles involved in signing produce the shapes needed to form the letters of the alphabet.
The data for this project is provided as zipped NumPy arrays with custom headers. In order to load these files, you will need to have the NumPy package installed.
The respective loadz primitive allows for a straight forwardloading of the datasets. The data is organized as follows:
The data for each label (handshape) is stored in a separate folder. Each folder contains .npz files. An npz file contains the data for one record (a matrix 8x400).
For more details, please refer to the paper.





