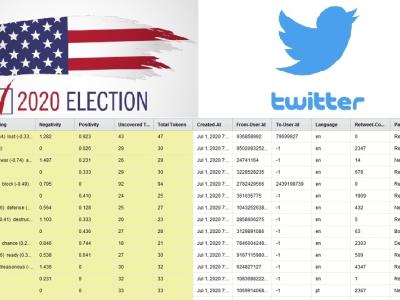
This dataset includes 24,201,654 tweets related to the US Presidential Election on November 3, 2020, collected between July 1, 2020, and November 11, 2020. The related party name and sentiment scores of tweets, also the words that affect the score were added to the data set.
- Categories: