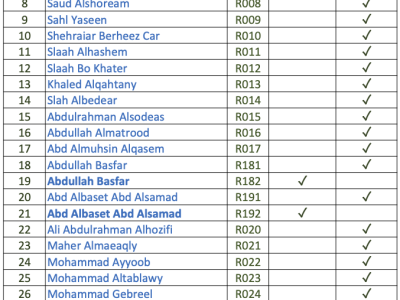
The dataset collected for the whole Quran; 114 sura (6236 ayah) recited by 35 Reciters (approximately 218000 audio files), downloaded from this website https://www.a-quran.com/showthread.php?t=11017, the audio files downloaded in mp3 format, all the downloaded files based on the Hafs from A’asim narration, the dataset figure shows reciters names who participate in this dataset.
- Categories:
