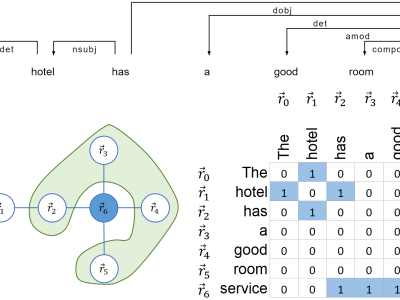
Topics modeling in computer science articles
- Citation Author(s):
-
Jose Melendez Barros
 (Universidade de São Paulo)
Rosa V. Encinas Quille
(Universidade de São Paulo)
Márcio Barbado Júnior
(Universidade de São Paulo)
Pedro Luiz Pizzigatti Corrêa
(Universidade de São Paulo)
Glauber de Bona
(Universidade de São Paulo)
Marcos Antonio Simplicio Jr
(Universidade de São Paulo)
(Universidade de São Paulo)
Rosa V. Encinas Quille
(Universidade de São Paulo)
Márcio Barbado Júnior
(Universidade de São Paulo)
Pedro Luiz Pizzigatti Corrêa
(Universidade de São Paulo)
Glauber de Bona
(Universidade de São Paulo)
Marcos Antonio Simplicio Jr
(Universidade de São Paulo)
- Submitted by:
- Jose Melendez
- Last updated:
- DOI:
- 10.21227/7exb-wb55
- Data Format:
- Links:
 560 views
560 views
- Categories:
- Keywords:
Abstract
By querying open data of notorious scientific databases via representational state transfers, and subsequently enforcing data management practices with a dynamic topic modeling approach on the referred metadata available, this work achieves a feasible form of article set analysis and classification. Research trends for a given field in specific moments are identified, and also the referred trends evolution throughout the years. It is then possible to detect the associated lexical variation overtime on published content, ultimately determining the so-called hot topics in arbitrary instants, including now. Three prominent scientific articles databases are probed by this work, they are arXiv, IEEExplore, and Springer Nature.
The dataset contains:
Identification of the articles used in the study
The proportion of the topics in each document
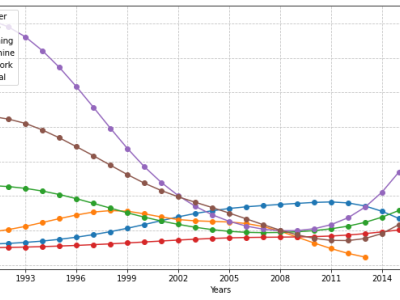
Number of articles per year per topic
Distribution of the words that make up each topic
Instructions:
Instructions and documentation are given in readme.pdf.
Dataset Files
- Identification of the articles used in the study (Size: 193.06 MB)
- Articles + abstracts used in the study (Size: 737.53 MB)
- Distribution of the topics in each document (Size: 978.98 MB)
- Number of articles per year per topic (Size: 3.96 KB)
- Distribution of the words that make up each topic top 50 (Size: 418.99 KB)
- Distribution of the words that make up each topic top 100 (Size: 853.12 KB)
- Distribution of the words that make up each topic top 200 (Size: 1.69 MB)