Synthetic Mobile Application Security Dataset for ML Vulnerability Detection
- Citation Author(s):
-
Ashley Audrey Innocent Yanguema
 (NANJING UNIVERSITY OF INFORMATION SCIENCE & TECHNOLOGY)
(NANJING UNIVERSITY OF INFORMATION SCIENCE & TECHNOLOGY)
- Submitted by:
- Ashley Yanguema
- Last updated:
- DOI:
- 10.21227/d68s-t550
- Data Format:
 27 views
27 views
- Categories:
- Keywords:
Abstract
This dataset contains synthetically generated data representing security profiles of mobile applications, designed for training and evaluating machine learning models for vulnerability detection. It was created as part of the research described in the paper "Machine Learning-Based Vulnerability Detection in Mobile Applications" by Yanguema and Yin.
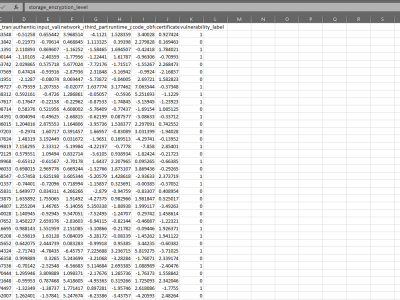
The dataset comprises 100 samples, each characterized by 10 engineered security features: `storage_encryption_level`, `api_security_score`, `data_transmission_security`, `authentication_strength`, `input_validation_score`, `network_communication_security`, `third_party_library_risk`, `runtime_permissions_management`, `code_obfuscation_level`, and `certificate_pinning_implementation`. These features are provided as raw numeric scores (floating-point). Each sample is labeled with a binary target variable, `vulnerability_label`, indicating the simulated presence (1) or absence (0) of security vulnerabilities.
The data generation process aimed to mirror realistic distributions and correlations relevant to mobile application security assessments. Note: The feature values in this file require normalization Min-Max scaling to [0,1] as a preprocessing step, as described in the associated paper's methodology, before being used for model training. This dataset can be used to reproduce the results presented in the associated paper, benchmark alternative machine learning approaches, and serve as a resource for research into automated mobile security analysis. The data is provided in CSV format.
Instructions:
Instructions for Use (Example - Reproducing Paper Results):
- Load the dataset, including the header (e.g., pandas in Python:
data = pd.read_csv('[mobile_app_vulnerabilities.csv]')). - Separate the features (X) from the target variable (y). (e.g.,
X = data.iloc[:, 0:10],y = data.iloc[:, 10]). - Apply a train/test split or cross-validation strategy (e.g., 70/30 split or 5-fold CV) before normalization. Ensure stratification based on the target variable 'y'.
- Calculate normalization parameters (e.g., min and max for Min-Max scaling) only from the training features (X_train).
- Apply the calculated normalization to both the training features (X_train_normalized) and the test features (X_test_normalized).
- Train a machine learning classifier (e.g., the neural network described in the paper) using the normalized training data (X_train_normalized, y_train).
- Evaluate the trained model on the normalized test data (X_test_normalized, y_test) using metrics like ROC-AUC, PR-AUC, etc.






