Shahmukhi Database SMDB- SMHaroof V1
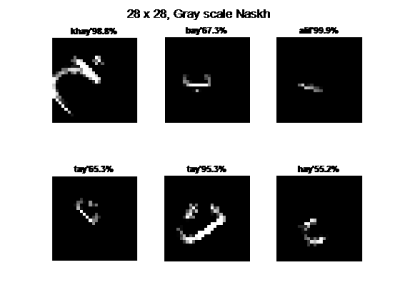
- Citation Author(s):
-
Humera Rafique
 (Hamdard Univeristy, SZABIST, Karachi)
Tariq Javid (Hamdard Univerity)
(Hamdard Univeristy, SZABIST, Karachi)
Tariq Javid (Hamdard Univerity) - Submitted by:
- humera rafique
- Last updated:
- DOI:
- 10.21227/24hn-tm42
- Data Format:
 232 views
232 views
Abstract
The greatest challenge of machine learning problems is to select suitable techniques and resources such as tools and datasets. Despite the existence of millions of speakers around the globe and the rich literary history of more than a thousand years, it is expensive to find the computational linguistic work related to Punjabi Shahmukhi script, a member of the Perso-Arabic context-specific script low-resource language family. The selection of the best algorithm for a machine learning problem heavily depends on the availability of a dataset for that specific task. We present a novel, custom-built, and first-of-its-kind dataset for Punjabi in Shahmukhi script, its design, development, and validation process using Artificial Neural Networks. The dataset uses up to 40 classes, in multiple fonts, including Nasta’leeq, Naskh, and Arabic Type, etc, many font sizes and has been presented in many sub sizes. The dataset has been designed with a special dataset construction process by which researchers can make changes in the dataset as per their requirements.* The dataset construction program can also perform data augmentation to generate millions of images for a machine learning algorithm with different parameters including font type, size orientation, and translation. Using this process, a dataset of any language can be constructed. CNNs in different architectures have been implemented and validation accuracy of up to 99% has been achieved.
Instructions:
Please read the SMDB guide file to understand the details. Different alphabets are saved in respective folders and folder names have been used as ground truth.