Psychometric tests dataset
- Citation Author(s):
-
Johne Marcus Jarske
 (Universidade de São Paulo)
Alessandra Gotuzo Seabra (Universidade Presbiteriana Mackenzie)
(Universidade de São Paulo)
Alessandra Gotuzo Seabra (Universidade Presbiteriana Mackenzie) - Submitted by:
- Johne Jarske
- Last updated:
- DOI:
- 10.21227/ktdv-rj19
- Data Format:
 2981 views
2981 views
- Categories:
- Keywords:
Abstract
Psychometric Data
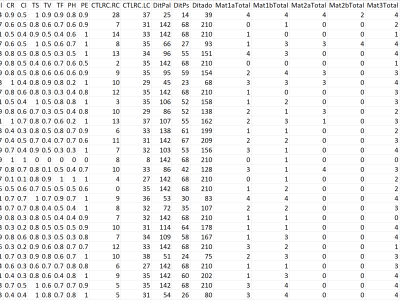
This dataset contains the results of the psychometric tests applied to a public school in the State of São Paulo, Brazil, involving 443 children, boys and girls, aged between 6 and 14, from the 1st to 4th grade of elementary school. From this database we extracted: i) WNw-RCT (Words and Non-words Reading Competence) attributes (correct regular words (CR), correct irregular words (CI), semantic changes (SC), visual changes (VC), phonological changes (PC), homophone non-words (HN) and weird non-words (WN)) and WNw- RCT-Total attribute (resulting from the sum of the seven WNw-RCT subtests); ii) AT (Arithmetic Test) attributes (Reading and writing numerical skills (AT-1A and AT-1B), Number counting (AT-2A and AT-2B), Higher-Low (AT-3)
Assembled accounts (AT-4), Dictated (AT-5) and Read questions (AT-6)) and the AT-Total attribute (resulting from the sum of the eight AT subtests; iii) CTLRC attributes (Contrastive Test of Listening and Reading Comprehension) (Listening Comprehension (LC) and Reading Comprehension (RC)); iv) WTD attributes (words (W) and non-words (NW)) and WDT-Total (resulting from the sum of the W and NW subtests), and; v) the students’ school grade and age.
The data on children who did not meet the age and school-grade ratio of the 1st grade between 6 and 7 years old, 2nd grade between 7 and 8 years old, 3rd grade between 8 and 9 years old and 4th grade between 9 and 10 years old were excluded from de dataset. The elements with missing data were also excluded from de dataset.
The dataset was a result of a research for assessment and cognitive intervention in students of taking elementary education. The study was approved by the research ethics committee, informed consent was obtained from parents and all privacy rights where observed. The study also followed the ethical guidelines recommended by the Standards for Educational and Psychological Testing.
The R language and the Kohonen package were used. The SOM algorithm was configured to generate a feature map containing 100 neurons - quadrangular neural network (10X10) with hexagonal topology, 2000 epochs as a stop condition and learning rate ranging from 0.5 to 0.01. The parameters were defined empirically, based on the following criteria: i) the Kohonen.som algorithm was chosen because it is the unsupervised version of the algorithm, provided by the Kohonen package; ii) the number of neurons on the map, considering that the network formed should have enough nodes to allow organizing the nodes on the map, so that they adequately reflected the information that regions on the map might present a higher concentration of input data, and at the same time, did not receive a formation containing empty neurons [28]; iii) the number of epochs determining the stopping condition of the algorithm, was determined by a function provided by the Kohonen package, which graphically allows observing the number of epochs necessary to stabilize the neural network [28]; iv) the learning rate was defined to be initially high (0.5), to allow the nodes to organize themselves for learning the topology of the data set, then reducing linearly up to 0.01 in the course of the iterations to allow the positioning refinement in the data space. For the analysis, we used the following SOM maps generated by the Kohonen package: i) codes show the SOM codebook vector in the form of colored circular sectioned elements; ii) property (heatmap), properties of each SOM map neuron are calculated and shown in color code. It can be used to visualize the similarity of one particular object to other objects in the dataset, to show the mean similarity of the neurons and objects mapped to them; and iii) mapping, shows in which neuron each object is mapped.







dsfada