IEEE BioCAS2024 Grand Challenge on Depression Detection
- Submission Dates:
- 05/31/2024 to 06/15/2024
- Citation Author(s):
- Submitted by:
- Yongfu Li
- Last updated:
- Fri, 05/31/2024 - 10:55
- DOI:
- 10.21227/xkfd-rt35
- Data Format:
- License:
- Creative Commons Attribution
 701 Views
701 Views- Categories:
- Keywords:
Abstract
We're excited to present a unique challenge aimed at advancing automated depression diagnosis. Traditional methods using written speech or self-reported measures often fall short in real-world scenarios. To address this, we've curated a dataset of authentic depression clinical interviews from a psychiatric hospital.
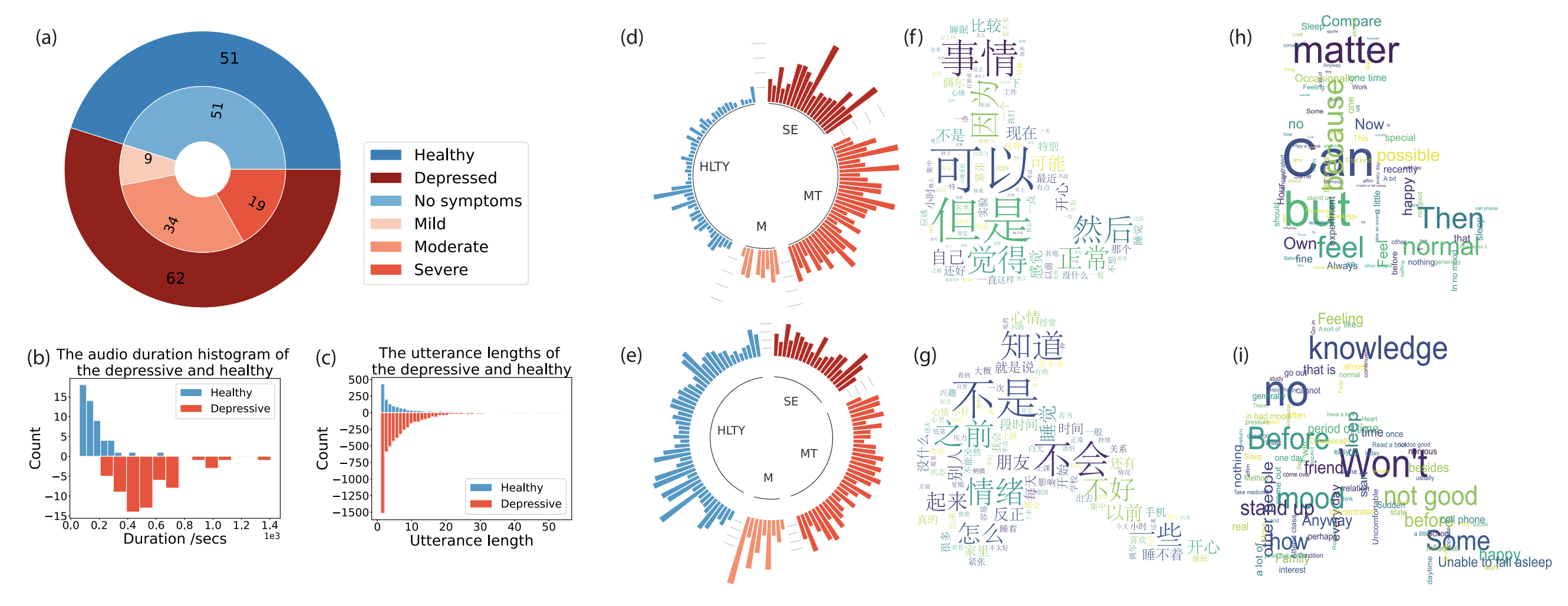
The dataset includes 113 recordings (89 for training and 24 for testing), featuring interactions with 52 healthy individuals and 61 diagnosed with depression. Each participant underwent assessments using the Montgomery-Asberg Depression Rating Scale (MADRS) in Chinese, with diagnoses confirmed by psychiatry specialists.
These interviews were meticulously audio-recorded, transcribed, and annotated by experienced physicians, ensuring data quality. Participants are tasked with developing machine learning models to detect depression presence and predict severity levels using audio and text features extracted from interviews.
Join us in leveraging this groundbreaking dataset to revolutionize depression diagnosis and advance mental health care. Let's make a difference together!
Instructions:
Data Files
train.zip - Contains 89 clinical interview audio recordings in MP3 format.
train_json.zip - Provides transcriptions for the corresponding audio recordings.
test.zip - Contains 24 clinical interview audio recordings in MP3 format.
test_json.zip - Provides transcriptions for the corresponding audio recordings.
train.csv - Metadata for the training set, including audio filenames, participant gender, and age.
test.csv - Metadata for the test set, including participant IDs, gender, and age.
sample_submission.csv - A template for participants to submit their predictions in the correct format.
Columns
Participant - Participant ID
File_name - File name of interview recording
Gender - Gender
Age - Age
Evaluation
create
more_horiz
keyboard_arrow_up
Binary Classification (Depression vs. Healthy):
For the binary classification task to distinguish between individuals with depression and those who are healthy, we will use the F1 score as the evaluation metric.
Multi-Class Classification (Depression Severity):
For the multi-class classification task predicting the severity of depression, we will utilize the micro-average F1 score as the evaluation metric. The micro-average F1 score calculates the average F1 score across all classes, considering the overall true positive, false positive, and false negative counts. Each class's F1 score is computed using the same formula as in binary classification.
Submission File
Please refer to sample_submission.csv to format your results.
Citation
Please cite the following article in your competition submission (if applicable):
@article{mao2023analysis, author={Mao, Kaining and Wang, Deborah Baofeng and Zheng, Tiansheng and Jiao, Rongqi and Zhu, Yanhui and Wu, Bin and Qian, Lei and Lyu, Wei and Chen, Jie and Ye, Minjie}, journal={IEEE Transactions on Biomedical Circuits and Systems}, title={Analysis of Automated Clinical Depression Diagnosis in a Chinese Corpus}, year={2023}, volume={17}, number={5}, pages={1135-1152}, keywords={Depression;Interviews;Recording;Machine learning;Multimodal sensors;Machine learning;Sentiment analysis;Medical diagnosis;Emotional corpora;machine learning;multimodal systems;nonverbal signals;sentiment analysis}, doi={10.1109/TBCAS.2023.3291554}}






Comments
Request dataset
Would like my students participate in the competition and hence requested to access the dataset.
NEED DATASET FOR COLLEGE PROJECT
PLEASE CAN YOU SHARE THE DATASET AS I NEED IT FOR MY COLLEGE PROJECT
shalini
Require dataset forresearch