vgg_sound_plus
- Citation Author(s):
-
Sangyeon Cho

- Submitted by:
- Sangyeon Jo
- Last updated:
- DOI:
- 10.21227/6gtg-kr60
- Data Format:
- Research Article Link:
 715 views
715 views
- Categories:
- Keywords:
Abstract
We construct the triple-modality dataset, VGG-sound+, comprising image-text-audio data. Based on VGG-sound, VGG-sound+ consists of 200,000 audio-visual data entries categorized as video data, including metadata label- ing the category of each video clip. We define the image-text-audio triplet modalities of VGG-sound+ as the dataset Di = (Ii , Ti , Ai), where Ii represents an image snap- shot of the video, Ti denotes a textual description of the video, and Ai signifies the audio clip.
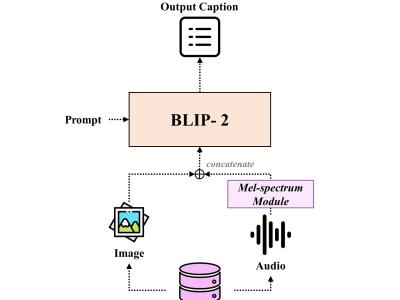
We extract random scenes from approximately 10 seconds-long video clips for Ii and capture the audio of the video clips for Ai . However, the VGG-sound dataset contains only metadata specifying the category of each video clip, without accompanying textual captions describing them in detail. Thus, we generate suitable captions Ti for the acquired Ii and Ai . Two approaches to captioning are considered: the semi-handcrafted method and the captioning model method. Inspired by previous image-text pre-training studies, the semi-handcrafted approach con- structs text description sets by randomly combining categories recorded in metadata with appropriate prompt templates (e.g., ’a photo and sound of [category]’). We devise 71 prompts for this training method. In contrast, the captioning model method uses extracted images and audio as inputs to generate text descriptions that include words recorded in the metadata. We use BLIP-2 as the captioning model.
Instructions:
columns = [ID, startseconds, label, train/test split, caption]
* ID : Youtube video ID.
* startseconds : The start time of the clip.
* label : categories of video.
* train/test split : Separate train-test defined by vgg-sound.
* caption : Generated caption







Apply for the dataset
In reply to Apply for the dataset by Liumeng Xue