PhishFOE Dataset
- Citation Author(s):
-
Yanche Ari Kustiawan
 (Multimedia University)
Khairil Imran Ghauth
(Multimedia University)
(Multimedia University)
Khairil Imran Ghauth
(Multimedia University)
- Submitted by:
- Yanche Kustiawan
- Last updated:
- DOI:
- 10.21227/tk80-5t77
- Data Format:
 130 views
130 views
- Categories:
- Keywords:
Abstract
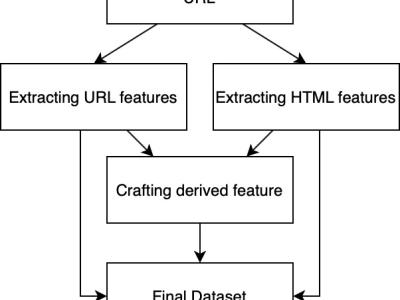
The PhishFOE Dataset is a comprehensive dataset designed for phishing URL detection using machine learning techniques. The dataset contains 101,083 URLs, with labeled features extracted from both the URL structure and HTML content of webpages. It provides insights into key characteristics that distinguish phishing websites from legitimate ones.
Total Samples: 101,063
Label:
0for Legitimate,1for PhishingNumber of Features: 32
This dataset can be utilized for training and testing machine learning models for phishing website detection, feature analysis, and security research.
Instructions:
1. Load the Dataset
import pandas as pd
df = pd.read_csv("PhishFOE_dataset.csv")
2. Feature Enggineering Function
def SuspiciousCharRatio(data):
data['SuspiciousCharRatio'] = (
data['NoOfObfuscatedChar'] +
data['NoOfEqual'] +
data['NoOfQmark'] +
data['NoOfAmp']
) / data['URLLength']
return data
def URLComplexityScore(data):
# Calculate the first term: (URLLength + NoOfSubDomain + NoOfObfuscatedChar) / URLLength
first_term = (
data['URLLength'] +
data['NoOfSubDomain'] +
data['NoOfObfuscatedChar']
) / data['URLLength']
# Calculate the second term: (NoOfEqual + NoOfAmp) / (NoOfQmark + 1)
second_term = (
data['NoOfEqual'] +
data['NoOfAmp']
) / (data['NoOfQmark'] + 1)
data['URLComplexityScore'] = first_term + second_term
return data
def HTMLContentDensity(data):
data['HTMLContentDensity'] = (
data['LineLength'] + data['NoOfImage']
) / (
data['NoOfJS'] + data['NoOfCSS'] + data['NoOfiFrame'] + 1
)
return data
def InteractiveElementDensity(data):
data['InteractiveElementDensity'] = (
data['HasSubmitButton'] +
data['HasPasswordField'] +
data['NoOfPopup']
) / (
data['LineLength'] + data['NoOfImage']
)
return data
3. Label Encoder
d = defaultdict(LabelEncoder)
df = df.apply(lambda x: d[x.name].fit_transform(x))
df_FS = df.copy()
y = df_FS['label']
X = df_FS.drop(columns=['label','URL'])
4. Boruta Feature Selector
def ranking(ranks, names, order=1):
minmax = MinMaxScaler()
ranks = minmax.fit_transform(order * np.array([ranks]).T).T[0]
ranks = map(lambda x: round(x, 2), ranks)
return dict(zip(names, ranks))
# Initialize RandomForestClassifier for Boruta
rf = RandomForestClassifier(
n_jobs=-1,
class_weight="balanced_subsample",
max_depth=5,
n_estimators="auto" # Adjust n_estimators to a specific value since 'auto' is not valid for this parameter
)
# Initialize Boruta Feature Selector
feat_selector = BorutaPy(rf, n_estimators='auto', random_state=1)
# Fit Boruta to the dataset
feat_selector.fit(X.values, y.values.ravel())
selected_features = X.columns[feat_selector.support_].tolist()
# Use only the selected features
X_selected = X[selected_features]
5. Split for model training
X_train, X_test, y_train, y_test = train_test_split(X_selected, y, test_size = 0.2, random_state = 42)
X_train.shape, y_train.shape, X_test.shape, y_test.shape






