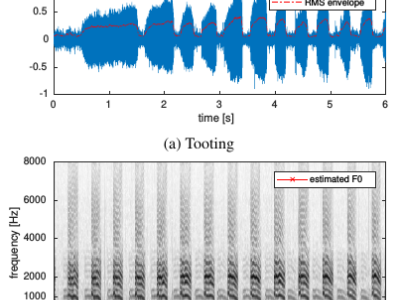
We introduce a novel dataset of bee piping audio signals which was built by collecting 44 different recordings which were published by various beekeepers on the YouTube platform.
Each recording has a duration varying from 2 to 13 seconds and is annotated according to the beekeeper comment respectively as Tooting or Quacking.
- Categories: