Text2RDF: LLM Fine-tuning Dataset for NER and RE
- Citation Author(s):
-
Jieping Liu
- Submitted by:
- jieping liu
- Last updated:
- DOI:
- 10.21227/mp21-2449
- Data Format:
 404 views
404 views
- Categories:
- Keywords:
Abstract
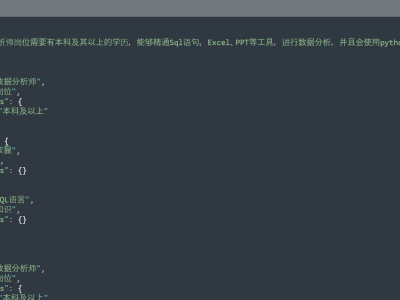
<p class="MsoNormal"><span lang="EN-US">The Text2RDF dataset is primarily designed to facilitate the transformation from text to RDF. It contains 1,000 annotated text segments, encompassing a total of 7,228 triplets. Utilizing this dataset to fine-tune large language models enables the models to extract triplets from text, which can ultimately be used to construct knowledge graphs. </span></p>
Instructions:
The Text2RDF dataset is primarily designed to facilitate the transformation from text to RDF. It contains 1,000 annotated text segments, encompassing a total of 7,228 triplets. Utilizing this dataset to fine-tune large language models enables the models to extract triplets from text, which can ultimately be used to construct knowledge graphs.







i want to finetune qwen to extract rdf triples for knowledge graph creation