Text-based depression detection dataset (Chinese)
- Citation Author(s):
-
Yating GUChi ZHANGXiaojian JIAShiguang NI
- Submitted by:
- Yating GU
- Last updated:
- DOI:
- 10.21227/zsfc-av84
- Data Format:
 703 views
703 views
- Categories:
- Keywords:
Abstract
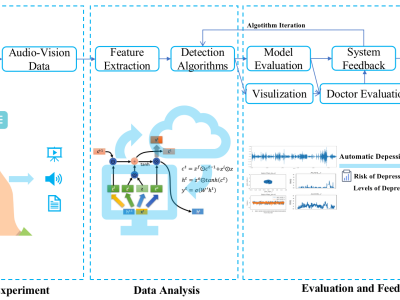
In this study, 31 Chinese patients diagnosed with depression (mean age 26.60±9.21) and 33 healthy control participants (mean age 26.00±7.36) participated, during which emotional picture descriptions and interview dialogues are collected. The experiment underwent review and received approval from the hospital's Bioethics Committee and the school's Medical Ethics Committee, and all the participants signed for the informed consent.
Instructions:
Files contain:
1) Audio Fragments: 16kHz audio fragments of all participants, divided into experiment dataset (named as par_num-1, for example, 22071102-1) and interview dataset (named as par_num-2, for example, 22071102-2).
2) Text Transcript: text transcript from the audio .pcm files, for example, ./Audio_Fragments/22071102/22071102-1/tra_1.pcm, tra_2.pcm..., tra_8.pcm will be transcripted to ./Text_Transcript/22071102/1_transcript.csv.
3) Par_score_brief.xlsx: the PHQ-9 score of the participants. The par-code column is the participant id that's related to the sub-folder name of the audio fragment file and the text transcript file.







.
hello,i want to request this dataset to process the clinical depression verified.
Could i use it?
Best Regards
Longd