NPI-RGCNAE
- Citation Author(s):
-
Han Yu (Tianjin University)Zi-ang Shen (Tianjin University)Pu-Feng Du (Tianjin University)
- Submitted by:
- Han Yu
- Last updated:
- DOI:
- 10.21227/qg28-fk76
- Links:
 247 views
247 views
- Categories:
- Keywords:
Abstract
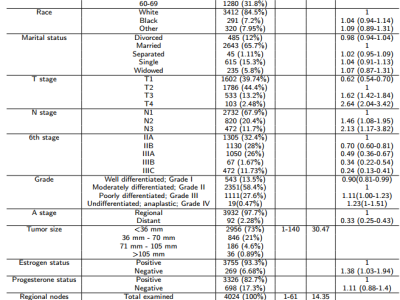
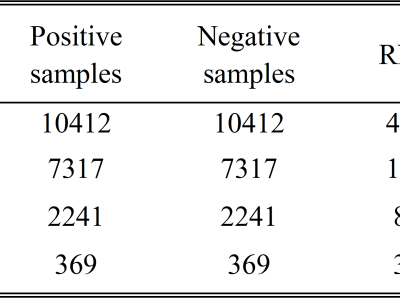
The original datasets are NPInter4158 [1], NPInter10412 [2], RPI7317 [3], RPI2241 [4], and RPI369 [4]. Only positive samples of them were used in our work.
We used a different strategy to select more reliable negative samples rather than randomly pairing, which was originally introduced by Zhang et al. in the LPI-CNNCP [5] study.
First, we calculated the Smith-Waterman similarity between each pair of proteins. Next, we calculated interaction scores between each pair of protein and RNA based on the known interaction pairs and protein similarities. Then, we sorted the interaction scores of all pairs in an ascending order. Finally, negative samples were selected sequentially from the head of the sorted list with the same number as positives.
[1] H. Zhang, Z. Ming, C. Fan, Q. Zhao, and H. Liu, “A path-based computational model for long non-coding RNA-protein interaction prediction,” Genomics, vol. 112, no. 2, pp. 1754–1760, Mar. 2020, doi: 10.1016/j.ygeno.2019.09.018.
[2] J. Yuan, W. Wu, C. Xie, G. Zhao, Y. Zhao, and R. Chen, “NPInter v2.0: an updated database of ncRNA interactions,” Nucl. Acids Res., vol. 42, no. D1, pp. D104–D108, Jan. 2014, doi: 10.1093/nar/gkt1057.
[3] X.-N. Fan and S.-W. Zhang, “LPI-BLS: Predicting lncRNA–protein interactions with a broad learning system-based stacked ensemble classifier,” Neurocomputing, vol. 370, pp. 88–93, Dec. 2019, doi: 10.1016/j.neucom.2019.08.084.
[4] U. K. Muppirala, V. G. Honavar, and D. Dobbs, “Predicting RNA-Protein Interactions Using Only Sequence Information,” BMC Bioinformatics, vol. 12, no. 1, p. 489, Dec. 2011, doi: 10.1186/1471-2105-12-489.
[5] S.-W. Zhang, X.-X. Zhang, X.-N. Fan, and W.-N. Li, “LPI-CNNCP: Prediction of lncRNA-protein interactions by using convolutional neural network with the copy-padding trick,” Analytical Biochemistry, vol. 601, p. 113767, Jul. 2020, doi: 10.1016/j.ab.2020.113767.
Instructions:
There are five datasets, including NPInter_4158, NPInter_10412, RPI369, RPI2241, RPI7317.
For each dataset,
- ncRNA.txt: records the name of ncRNAs.
- protein.txt: records the name of proteins.
- ncRNA_extracted_seq.fasta: corresponding ncRNA sequences in the fasta format.
- protein_extracted_seq.fasta: corresponding protein sequences in the fasta format.
- Protein3merfeat.csv: 3-mer frequencies of proteins in the protein.txt.
- ncRNA4merfeat.csv: 4-mer frequencies of RNAs in the ncRNA.txt.
- Positives.csv: original positive pairs. The index of proteins and RNAs corresponds to the order in protein.txt and ncRNA.txt respectively. The index starts from zero.
- Negatives.csv: All possible negative sample pairs. The label of each pair is the probability of interacting.
- protein sw_smilarity matrix.csv:Smith-Waterman similarity between each pair of proteins in protein.txt .
- edgelist_random.csv: contains postive pairs and negative pairs. The negative sample set was generated by randomly pairing RNAs and proteins, with exceptions on known interacting pairs.
- edgelist_sort_random.csv: contains postive pairs and negative pairs. The negative sample set was generated by three steps: (1) Sort interaction scores in Negatives.csv in an ascending order. (2) Pick negative samples sequentially from the head of the sorted list with twice the number of positive samples. (3) Randomly select half of the negative samples as the final negative sample set.
- edgelist_sort.csv: contains postive pairs and negative pairs. The negative sample set was generated by two steps: (1) Sort interaction scores in Negatives.csv in an ascending order. (2) Pick negative samples sequentially from the head of the sorted list with the same number of positive samples.
- NPI_pos.csv: A Binary matrix. 1 indicates the RNA corresponding to the row number interacts with the protein corresponding to the column number. 0 indicates unknown relationship.
- NPI_neg_random.csv: A Binary matrix. 1 corresponds the negative sample pair in the edgelist_random.csv. 0 indicates unknown relationship.
- NPI_neg_sort.csv: A Binary matrix. 1 corresponds the negative sample pair in the edgelist_sort.csv. 0 indicates unknown relationship.
- NPI_neg_sort_random.csv: A Binary matrix. 1 corresponds the negative sample pair in the edgelist_sort_random.csv. 0 indicates unknown relationship.