CSTNET
- Citation Author(s):
-
Aamina Hassan
- Submitted by:
- Aamina Hassan
- Last updated:
- DOI:
- 10.21227/4394-fv34
- Data Format:
 224 views
224 views
- Categories:
- Keywords:
Abstract
The increasing prevalence of encrypted traffic in
modern networks poses significant challenges for network security,
particularly in detecting and classifying malicious activities
and application signatures. To overcome this issue, deep learning
has turned out to be a promising candidate owing to its ability
to learn complex data patterns. In this work, we present a
deep learning-based novel and robust framework for encrypted
traffic analysis (ETA) which leverages the power of Bidirectional
Encoder Representations from Transformers (BERT) and Long
Short-Term Memory (LSTM) networks. Our proposed framework
leverages the capability of LSTM to capture long-term
dependencies in sequential data for modeling the temporal patterns
of network packets, while BERT enhances this by providing
an understanding of the bidirectional context within packet
sequences. Hence, this approach of ETA relies on LSTM for
enabling effective detection of anomalies and prediction of future
packet where BERT provides a deeper contextual understanding
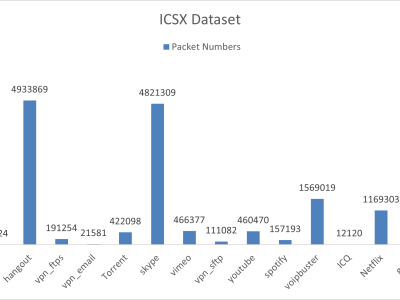
of the traffic flow. Publicly available dataset ISCXVPN2016
and CSTNET are used to test our proposed framework which
outperformed the existing works by yielding an accuracy rate
(AC) of 99.65%, precision (PR) of 99.53% and recall (RC) of
99.28%. The proposed framework serves to efficiently detect
Over-the-Top (OTT) application signatures within encrypted
traffic streams, ensuring comprehensive network monitoring and
enhanced security measures without compromising the integrity
of packets.
Instructions:
Description of processing PCAP files to generate dataset
For PCAP data, it is recommended to clean it first. Since the program processing logic is not smooth, we detail the data pre-processing for pre-training and fine-tuning as followed.
Pre-training Stage
Main Program: dataset_generation.py
Functions: pretrain_dataset_generation, get_burst_feature
Initialization.
Set the variablepcap_path(line:616) as the directory of PCAP data to be processed.
Set the variableword_dir(line:23) andword_name(line:24) as the storage directory of pre-training daraset.Pre-process PCAP.
Set the variableoutput_split_path(line:583) andpcap_output_path(line:584).
Thepcap_output_pathindicates the storage directory where the pcapng format of PCAP data is converted to pcap format.
Theoutput_split_pathrepresents the storage directory for PCAP data slicing into session format.Gnerate Pre-training Datasets.
Following the completion of PCAP data processing, the program generates a pre-training dataset composed of BURST.
Fine-tuning Stage
Main Program: main.py
Functions: data_preprocess.py, dataset_generation.py, open_dataset_deal.py, dataset_cleanning.py
The key idea of the fine-tuning phase when processing public PCAP datasets is to first distinguish folders for different labeled data in the dataset, then perform session slicing on the data, and finally generate packet-level or flow-level datasets according to sample needs.
Note: Due to the complexity of the possible existence of raw PCAP data, it is recommended that the following steps be performed to check the code execution when it reports an error.
Initialization.
pcap_path,dataset_save_path,samples,features,dataset_level(line:28) are the basis variables, which represent the original data directory, the stored generated data directory, the number of samples, the feature type, and the data level.open_dataset_not_pcap(line:215) represents the processing of converting PCAP data to pcap format, e.g. pcapng to pcap.
Andfile2dir(line:226) represents the generation of category directories to store PCAP data when a pcap file is a category.Pre-process.
The data pre-processing is primarily to split the PCAP data in the directory into session data.
Please set thesplitcap_finishparameter to 0 to initialize the sample number array, and the value ofsampleset at this time should not exceed the minimum number of samples.
Then you can setsplitcap=True(line:54) and run the code for splitting PCAP data. The splitted sessions will be saved inpcap_path\\splitcap.Generation.
After data pre-processing is completed, variables need to be changed for generating fine-tuned training data. Thepcap_pathshould be the path of splitted data and setsplitcap=False. Now thesamplecan be unrestricted by the minimum sample size. Theopen_dataset_not_pcapandfile2dirshould be False. Then the dataset for fine-tuning will be generated and saved indataset_save_path.






