AirScript: A Surface Electromyography (sEMG) Dataset for Airwriting Recognition
- Citation Author(s):
-
Atiqa Saeed
 (Department of Biomedical Engineering and Sciences, School of Mechanical and Manufacturing Engineering, National University of Sciences and Technology (NUST), Islamabad 44000, Pakistan )
Asim Waris
(Department of Biomedical Engineering and Sciences, School of Mechanical and Manufacturing Engineering, National University of Sciences and Technology (NUST), Islamabad 44000, Pakistan )
Motab Turki AlMousa (Department of Electrical Engineering, School of Engineering, Prince Sattam Bin Abdul Aziz University, Al-Kharj, Saudi Arabia)Jawad Khan
(Department of Electrical Engineering, School of Engineering, Prince Sattam Bin Abdul Aziz University, Al-Kharj, Saudi Arabia)
(Department of Biomedical Engineering and Sciences, School of Mechanical and Manufacturing Engineering, National University of Sciences and Technology (NUST), Islamabad 44000, Pakistan )
Asim Waris
(Department of Biomedical Engineering and Sciences, School of Mechanical and Manufacturing Engineering, National University of Sciences and Technology (NUST), Islamabad 44000, Pakistan )
Motab Turki AlMousa (Department of Electrical Engineering, School of Engineering, Prince Sattam Bin Abdul Aziz University, Al-Kharj, Saudi Arabia)Jawad Khan
(Department of Electrical Engineering, School of Engineering, Prince Sattam Bin Abdul Aziz University, Al-Kharj, Saudi Arabia)
- Submitted by:
- Atiqa Saeed
- Last updated:
- DOI:
- 10.21227/nj4g-qb36
- Data Format:
 364 views
364 views
- Categories:
- Keywords:
Abstract
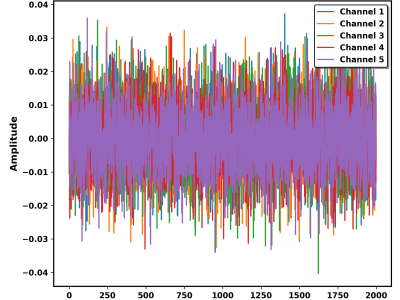
The 'AirScript' dataset consists of surface electromyography (sEMG) signals obtained while writing the uppercase English alphabets (A–Z) in free space. The Delsys Trigno device was used to record forearm muscle activity from 16 subjects. Every subject performs two trials for each letter, thus resulting in 52 samples per subject. sEMG signals obtained from all subjects were stored at a 2000 Hz sampling rate for high temporal resolution. The dataset consists of raw sEMG signals that are stored in subject-specific folders and saved as `.npy` files. Electrodes were placed on the flexor and extensor muscles of the forearm such as Flexor Pollicis Longus, Flexor Carpi Radialis, Extensor Digitorum, Flexor Carpi Ulnaris, and Brachioradialis. This process was enabled by a custom-built Graphical user interface (GUI) using Tkinter, which automate the display of instruction during the air writing task. The Delsys Trigno system records signals from five channels capturing muscle activity during contraction for each trial. The dataset is suitable for studies in EMG-based alphabet categorization, gesture recognition, and human-computer interaction. In addition to advancing wearable technologies, this dataset aids in the development of deep-learning models for precise air writing identification.
Instructions:
Dataset Structure
The dataset is organized into a main folder named AirScript containing 16 subfolders (1 to 16), each representing a participant.
Inside each participant folder are 52 .npy files corresponding to the English uppercase alphabets, with two trials per letter.
File naming convention:
A_TRIAL_1.npy: Data for the first trial of the letter "A".
B_TRIAL_2.npy: Data for the second trial of the letter "B".
This pattern continues for all 26 letters.
File Format
Each .npy file contains raw sEMG signals as a NumPy array.
The data shape is (n, c), where:
n is the number of data points (varies due to different writing speeds).
c is the number of channels used (5 channel for this dataset).