Open Access Entries from this Author
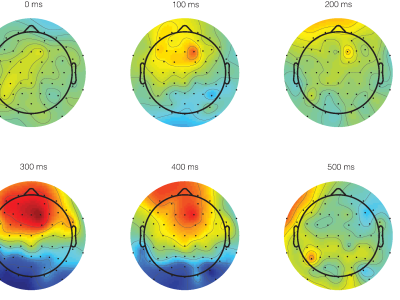
The dataset consists of EEG recordings obtained when subjects are listening to different utterances : a, i, u, bed, please, sad. A limited number of EEG recordings where also obtained when the three vowels were corrupted by white and babble noise at an SNR of 0dB. Recordings were performed on 8 healthy subjects.
- Categories:
-