tri-modal dataset
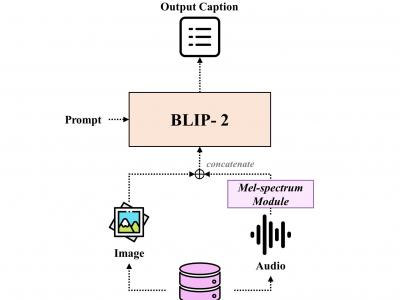
We construct the triple-modality dataset, VGG-sound+, comprising image-text-audio data. Based on VGG-sound, VGG-sound+ consists of 200,000 audio-visual data entries categorized as video data, including metadata label- ing the category of each video clip. We define the image-text-audio triplet modalities of VGG-sound+ as the dataset Di = (Ii , Ti , Ai), where Ii represents an image snap- shot of the video, Ti denotes a textual description of the video, and Ai signifies the audio clip.
- Categories:
 712 Views
712 Views