Datasets
Standard Dataset
Glaucoma Screening dataset
- Citation Author(s):
- Submitted by:
- Zeru Hai
- Last updated:
- Mon, 09/09/2024 - 05:21
- DOI:
- 10.21227/b2r5-5z41
- Data Format:
- Research Article Link:
- License:
 616 Views
616 Views- Categories:
- Keywords:
Abstract
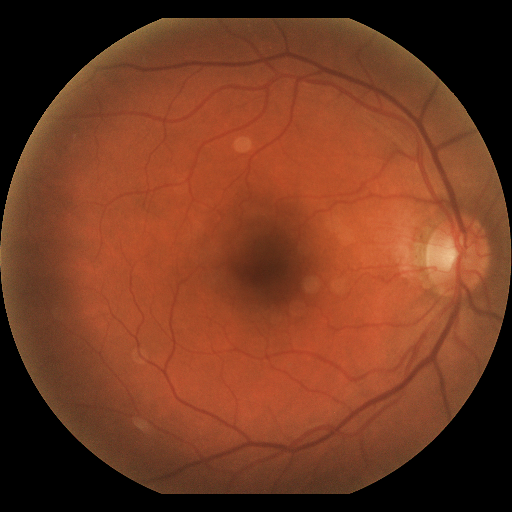
PAPILA dataset contains fundus images and clinicaldata from 244 patients, with images from both eyes of each patient. This dataset is specifically designed to support research on early glaucoma diagnosis by leveraging comprehensive data from both eyes. Additionally, it includes segmentation information for each patient’s optic disc and cup, alongside diagnostic outcomes based on clinical data. For our analysis, we focused on images labeled as normal (0) and glaucoma (1),selecting data from 210 patients. The subset included 333 non-glaucoma images and 87 glaucoma images.
OIA-ODIR dataset is a comprehensive public resource containing over 8,000 high-resolution fundus images from more than 5,000 patients. This dataset includes various ocular diseases such as glaucoma, diabetic retinopathy, and age-related macular degeneration. Alongside retinal images, it provides associated clinical information. For our study, we selected 223 high-quality fundus images of glaucoma patients from the training set, along with 421 images from normal individuals and patients with other ocular diseases. We used 20% of these images as our validation set. From the test set, we selected 91 quality-screened fundus images of glaucoma patients and 165 images from normal individuals and those with other ocular diseases.
ORIGA dataset is a specialized resource for glaucoma analysis, containing 650 high-resolution retinal fundus images, including 168 glaucoma and 482 normal images. Curated by the Singapore National Eye Centre (SNEC) and the National University of Singapore (NUS), this dataset provides detailed diagnostic labels and related clinical information, serving as a valuable resource for training glaucoma detection models.
REFUGE dataset is specifically curated for glaucoma detection and analysis, featuring 1,200 high-resolution retinal fundus images annotated with optic disc and cup regions. This dataset, collected by various international research institutions and hospitals, is aimed at advancing automated glaucoma detection and image segmentation. For our analysis, we used fundus images from the training and validation sets as our test set, which included 720 normal and 80 glaucoma images, as the test set labels are not provided.
The PAPILA, OIA-ODIR, ORIGA, and REFUGE datasets provide extensive resources for advancing glaucoma detection research. PAPILA includes fundus images and clinical data from 244 patients, offering detailed segmentation of optic discs and diagnostic outcomes, with a focus on 333 non-glaucoma and 87 glaucoma images from 210 patients. OIA-ODIR features over 8,000 images from more than 5,000 patients, including various ocular diseases, from which 644 images were used for our study, divided into training and validation sets. ORIGA, curated by the Singapore National Eye Centre and National University of Singapore, contains 650 images with detailed diagnostic labels for training models. Lastly, the REFUGE dataset, aimed at glaucoma analysis, includes 1,200 annotated images used in our test set, providing a significant sample for automated detection and segmentation studies. These datasets collectively support robust research on early glaucoma diagnosis by leveraging comprehensive data, detailed annotations, and a broad spectrum of clinical information.
Documentation
| Attachment | Size |
|---|---|
| 15 KB |






Comments
。