Artificial Intelligence

We have selected the ImageNet validation set and the Flower dataset as benchmark standards for the image classification domain. These datasets provide a robust and diverse set of images, ensuring a comprehensive evaluation of model performance. For benchmark testing in the object detection domain, we utilize the COCO2012 validation set and the Road Voc dataset. These datasets are well-suited for assessing the accuracy and efficiency of object detection models in various real-world scenarios.
- Categories:
 79 Views
79 Views
This dataset is the dataset used in article 'A Multi-tropical Cyclone Trajectory Prediction Method Based on a Density Map with Memory and Data Fusion' by Dongfang Ma, Zhaoyang Ma, Chengying Wu and Jianmin Lin. The authors are with the Institute of Marine Sensing and Networking, Ocean College, Zhejiang University, Zhoushan 316021, China. This dataset contains satellite images, density maps of TC locations and geopotential height maps.
- Categories:
57 Views
The robot arm system with no or low-accuracy Lagrange dynamic identification is a typical unknown-structure MIMO coupled system. It is difficult to achieve fast-convergence and high-accuracy control for this practical system, especially with no empirical pre-adjustment of the initial input direction. To solve this practical problem, a novel prescribed finite-time nondirectional AT-S fuzzy control method is proposed.
- Categories:
116 Views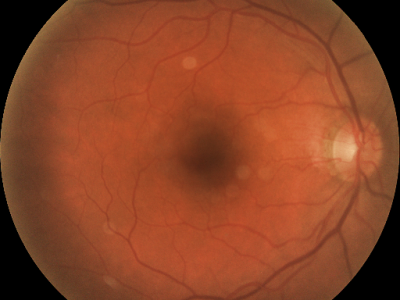
PAPILA dataset contains fundus images and clinicaldata from 244 patients, with images from both eyes of each patient. This dataset is specifically designed to support research on early glaucoma diagnosis by leveraging comprehensive data from both eyes. Additionally, it includes segmentation information for each patient’s optic disc and cup, alongside diagnostic outcomes based on clinical data. For our analysis, we focused on images labeled as normal (0) and glaucoma (1),selecting data from 210 patients.
- Categories:
358 Views
The operator controls the vehicle to drive in an environment with dense distribution of obstacles. During the driving process, the spatial environment data is collected by liDAR and camera, and the map of the operable area is processed according to the change of longitudinal slope, which is used to show the distribution of the operable area in the current driving space of the vehicle. Then, according to the distribution of operable areas and driving behavior data, the study of humanoid driving is carried out.
- Categories:
278 Views
To download the dataset without purchasing an IEEE Dataport subscription, please visit: https://zenodo.org/records/13738598
Please cite the following paper when using this dataset:
- Categories:
948 Views
This dataset offers a comprehensive collection of financial data associated with the development of medical software, providing insights into the various cost components involved in creating and maintaining such systems. It encompasses expenses from the initial concept and design phase through to development, testing, deployment, and ongoing maintenance. The data has been meticulously gathered from a variety of completed and ongoing medical software projects, highlighting both typical and outlier cost scenarios.
- Categories:
35 Views
This dataset contains information about code smell, which is a very important issue in software engineering.
It is built by collecting the method having code smell from GitHub using the SonarCloud tool.
There are 5 code smells and 1 normal class with 500 examples each.
the metadata: method (function),smellkey, smellid
Smell Type
ID
Description
Reference
java:S100
0
- Categories:
464 Views
5G cellular networks are particularly vulnerable against narrowband jammers that target specific control subchannels in the radio signal. One mitigation approach is to detect such jamming attacks with an online observation system, based on machine learning. We propose to detect jamming at the physical layer with a pre-trained machine-learning model that performs binary classification. Based on data from an experimental 5G network, we study the performance of different classification models.
- Categories:
258 Views
This dataset contains audio recordings and transcriptions of toxic speech derived from Indonesian conversations during YouTube videos where scammers are confronted. The dataset captures two separate interactions that escalate into toxic exchanges. Each interaction has been verified by native Indonesian speakers and labeled into two classes: toxic and non-toxic. The dataset includes both the original and preprocessed versions of the speech and text data. The original speech files total 136MB, while the preprocessed speech files are 111,7MB.
- Categories:
207 Views