Artificial Intelligence

Presented here is a dataset used for our SCADA cybersecurity research. The dataset was built using our SCADA system testbed described in our paper below [*]. The purpose of our testbed was to emulate real-world industrial systems closely. It allowed us to carry out realistic cyber-attacks.
- Categories:
 2224 Views
2224 Views
The dataset comprises of image file s of size 20 x 20 pixels for various types of metals and non-metal.The data collected has been augmented, scaled and modified to represent a number a training set dataset.It can be used to detect and identify object type based on material type in the image.In this process both training data set and test data set can be generated from these image files.
- Categories:
1975 Views
Dataset for the paper entitled "Interactive Dual Attention Network for Text Sentiment Classification"
- Categories:
145 Views
The Dataset
We introduce a novel large-scale dataset for semi-supervised semantic segmentation in Earth Observation: the MiniFrance suite.
- Categories:
6333 Views
We introduce a new database of voice recordings with the goal of supporting research on vulnerabilities and protection of voice-controlled systems (VCSs). In contrast to prior efforts, the proposed database contains both genuine voice commands and replayed recordings of such commands, collected in realistic VCSs usage scenarios and using modern voice assistant development kits.
- Categories:
1802 Views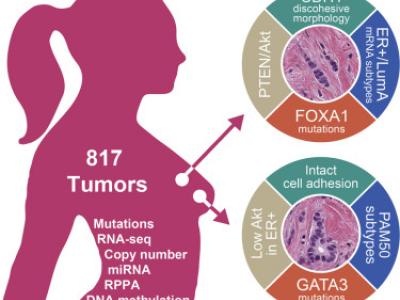
Invasive lobular carcinoma (ILC) is the second most prevalent histologic subtype of invasive breast cancer. Here, we comprehensively profiled 817 breast tumors, including 127 ILC, 490 ductal (IDC), and 88 mixed IDC/ILC. Besides E-cadherin loss, the best known ILC genetic hallmark, we identified mutations targeting PTEN, TBX3 and FOXA1 as ILC enriched features. PTEN loss associated with increased AKT phosphorylation, which was highest in ILC among all breast cancer subtypes. Spatially clustered FOXA1 mutations correlated with increased FOXA1 expression and activity.
- Categories:
626 Views
This dataset is a large-scale Chinese hotel review data set collected by Tan Songbo. The corpus size is 10,000 reviews. The corpus is automatically collected and organized from Trip.com.
- Categories:
1178 Views
This dataset was created from all Landsat-8 images from South America in the year 2018. More than 31 thousand images were processed (15 TB of data), and approximately on half of them active fire pixels were found. The Landsat-8 sensor has 30 meters of spatial resolution (1 panchromatic band of 15m), 16 bits of radiometric resolution and 16 days of temporal resolution (revisit). The images in our dataset are in TIFF (geotiff) format with 10 bands (excluding the 15m panchromatic band).
- Categories:
6333 Views
Spoken Indian Language Identification Database
(9 languages, 8 different utterance lengths)
Languages
- Assamese
- Bengali
- Gujarati
- Hindi
- Kannada
- Malayalam
- Marathi
- Tamil
- Telugu
Durations
- 30 sec
- 10 sec
- 5 sec
- 3 sec
- 1 sec
- 0.5 sec
- 0.2 sec
- 0.1 sec
- Categories:
1131 Views
We present GeoCoV19, a large-scale Twitter dataset related to the ongoing COVID-19 pandemic. The dataset has been collected over a period of 90 days from February 1 to May 1, 2020 and consists of more than 524 million multilingual tweets. As the geolocation information is essential for many tasks such as disease tracking and surveillance, we employed a gazetteer-based approach to extract toponyms from user location and tweet content to derive their geolocation information using the Nominatim (Open Street Maps) data at different geolocation granularity levels. In terms of geographical coverage, the dataset spans over 218 countries and 47K cities in the world. The tweets in the dataset are from more than 43 million Twitter users, including around 209K verified accounts. These users posted tweets in 62 different languages.
- Categories:
5586 Views