Artificial Intelligence

NCBI: The NCBI dataset is a biomedical corpus containing 793 PubMed abstracts, each manually annotated to include disease mentions and their corresponding concepts, providing a high-quality gold standard for disease name recognition and normalization research.
- Categories:
 93 Views
93 Views
This dataset comprises audio recordings of ultra-high-frequency ambient noise stored in the lossless waveform format (WAW). The recordings were sampled at a frequency sample rate of 2.048 MHz and then provided at a downsampled audio rate of 48 kHz for compatibility and practical usage. The total length of the dataset is 01:30:29, consisting of approximately 260 million data points. (2024-03-30)
- Categories:
20 Views
In our ever-expanding world of advanced satellite and communications systems, there's a growing challenge for passive radiometer sensors used in the Earth observation like 5G. These passive sensors are challenged by risks from radio frequency interference (RFI) caused by anthropogenic signals. To address this, we urgently need effective methods to quantify the impacts of 5G on Earth observing radiometers. Unfortunately, the lack of substantial datasets in the radio frequency (RF) domain, especially for active/passive coexistence, hinders progress.
- Categories:
436 Views
In Tibetan culture, Thangka art holds a significant status and is known as the "Encyclopedia of the Tibetan culture". This unique art form of painting encompasses multiple aspects of Tibetan history, politics, culture, and social life, and serves as precious material for studying Tibetan culture. Considering the lack of publicly available Thangka dataset, We constructed a thangka image super-resolution dataset in our research.
- Categories:
16 Views
Anomaly detection plays a crucial role in various domains, including but not limited to cybersecurity, space science, finance, and healthcare. However, the lack of standardized benchmark datasets hinders the comparative evaluation of anomaly detection algorithms. In this work, we address this gap by presenting a curated collection of preprocessed datasets for spacecraft anomalies sourced from multiple sources. These datasets cover a diverse range of anomalies and real-world scenarios for the spacecrafts.
- Categories:
753 Views
To access this dataset without purchasing an IEEE Dataport subscription, please visit: https://zenodo.org/doi/10.5281/zenodo.11711229
Please cite the following paper when using this dataset:
- Categories:
801 Views
The Garbage Image Dataset consists of images of garbage items collected from nearby localities using smartphones. The dataset is categorized into five different classes. Each category represents a specific type of garbage item commonly found in everyday waste. The purpose of the Garbage Image Dataset is to provide a collection of labelled images of garbage items from different categories. The dataset can be used to train and evaluate deep learning models for garbage classification tasks.
- Categories:
715 Views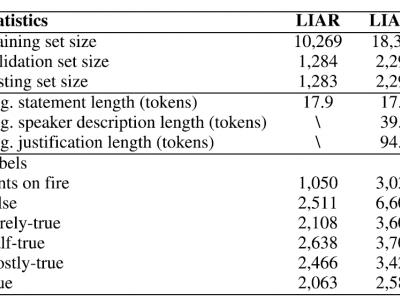
The LIAR dataset has been widely followed by fake news detection researchers since its release, and along with a great deal of research, the community has provided a variety of feedback on the dataset to improve it. We adopted these feedbacks and released the LIAR2 dataset, a new benchmark dataset of ~23k manually labeled by professional fact-checkers for fake news detection tasks.
- Categories:
177 Views
Image representation of Malware-benign dataset. The Dataset were compiled from various sources malware repositories: The Malware-Repo, TheZoo,Malware Bazar, Malware Database, TekDefense. Meanwhile benign samples were sourced from system application of Microsoft 10 and 11, as well as open source software repository such as Sourceforge, PortableFreeware, CNET, FileForum. The samples were validated by scanning them using Virustotal Malware scanning services. The Samples were pre-processed by transforming the malware binary into grayscale images following rules from Nataraj (2011).
- Categories:
332 Views
The "MANUU: Handwritten Urdu OCR Dataset" is an extensive and meticulously curated collection to advance OCR (Optical Character Recognition) for handwritten Urdu letters, digits, and words. The compilation of the dataset has been conducted methodically, ensuring that it encompasses a wide variety of handwritten instances. This comprehensive collection enables the construction and assessment of strong models for Optical Character Recognition (OCR) systems specifically designed for the complexities of the Urdu script.
- Categories:
543 Views