Machine Learning

The SINEW 15 Biomarker dataset was extracted from the sensor data collected by a longitudinal study called Sensors IN-home for Elder Wellbeing (SINEW).
- Categories:
 40 Views
40 Views
This dataset presents the capacity fade data for eight Lithium Titanate Oxide (LTO) battery cells over progressive charge-discharge cycles. The measurements, recorded at intervals of 250 cycles up to 3500 cycles, track the aging effects on battery capacity over time. The aging procedure includes a rest period of 10 minutes between charging and discharging cycles. Each charging and discharging process was conducted with a constant current of 1 ampere (A). The maximum charge voltage was set to 2.75 volts (V), while the minimum discharge voltage was set at 1.30 V.
- Categories:
213 Views
This dataset contains a comprehensive V2X misbehavior dataset simulated using VASP, an open-source framework. VASP allows the simulation of diverse types of V2X attacks and works as a sub-module for Veins, a well-established open-source framework for running vehicular network simulations. Veins runs on an event-based network simulator OMNeT ++, and road traffic simulator SUMO. Data are collected from the Boston traffic network, which is a good candidate to represent real-world traffic mobility. We run VASP simulation for 3,000 simulated seconds to collect benign traces without any attacks.
- Categories:
189 Views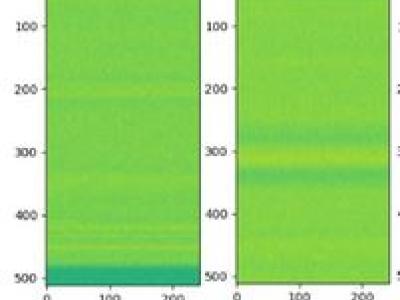
Interference signals degrade and disrupt Global Navigation Satellite System (GNSS) receivers, impacting their localization accuracy. Therefore, they need to be detected, classified, and located to ensure GNSS operation. State-of-the-art techniques employ supervised deep learning to detect and classify potential interference signals. We fuse both modalities only from a single bandwidth-limited low-cost sensor, instead of a fine-grained high-resolution sensor and coarse-grained low-resolution low-cost sensor.
- Categories:
403 Views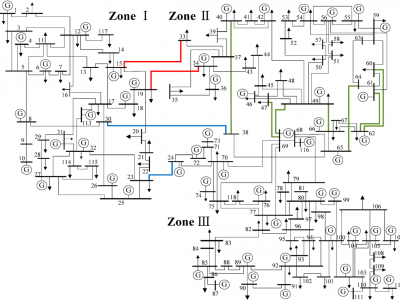
This dataset consists of high-dimensional data streams collected from a cyber-physical 118-bus power system, offering a valuable resource for fault diagnosis and classification in large-scale smart grids.
- Categories:
419 Views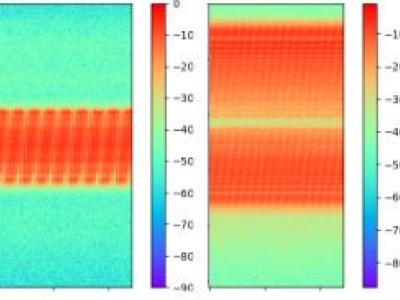
Jamming devices pose a significant threat by disrupting signals from the global navigation satellite system (GNSS), compromising the robustness of accurate positioning. Detecting anomalies in frequency snapshots is crucial to counteract these interferences effectively. The ability to adapt to diverse, unseen interference characteristics is essential for ensuring the reliability of GNSS in real-world applications. We recorded a dataset with our own sensor station at a German highway with eight interference classes and three non-interference classes.
- Categories:
153 Views
Optical remote sensing images, with their high spatial resolution and wide coverage, have emerged as invaluable tools for landslide analysis. Visual interpretation and manual delimitation of landslide areas in optical remote sensing images by human is labor intensive and inefficient. Automatic delimitation of landslide areas empowered by deep learning methods has drawn tremendous attention in recent years. Mask R-CNN and U-Net are the two most popular deep learning frameworks for image segmentation in computer vision.
- Categories:
68 Views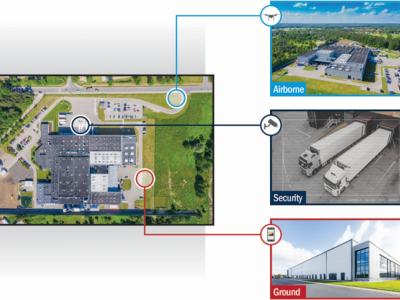
Since the aircraft trajectory data in the field of air traffic management typically lacks labels, it limits the community's ability to explore classification models. Consequently, evaluations of clustering models often focus on the correctness of cluster assignment rather than merely the closeness within the cluster. To address this, we labeled the dataset for both classification and clustering tasks by referring to aeronautical publications. The process of obtaining the ATFM trajectory dataset consists of data sourcing, preprocessing, and annotation.
- Categories:
141 Views
This dataset used in the research paper "JamShield: A Machine Learning Detection System for Over-the-Air Jamming Attacks." The research was conducted by Ioannis Panitsas, Yagmur Yigit, Leandros Tassiulas, Leandros Maglaras, and Berk Canberk from Yale University and Edinburgh Napier University.
For any inquiries, please contact Ioannis Panitsas at ioannis.panitsas@yale.edu.
- Categories:
145 Views